diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 246b467d8b04..52d8988206f1 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -148,6 +148,8 @@
title: Audio Diffusion
- local: api/pipelines/audioldm
title: AudioLDM
+ - local: api/pipelines/controlnet
+ title: ControlNet
- local: api/pipelines/cycle_diffusion
title: Cycle Diffusion
- local: api/pipelines/dance_diffusion
@@ -203,8 +205,6 @@
title: Self-Attention Guidance
- local: api/pipelines/stable_diffusion/panorama
title: MultiDiffusion Panorama
- - local: api/pipelines/stable_diffusion/controlnet
- title: Text-to-Image Generation with ControlNet Conditioning
- local: api/pipelines/stable_diffusion/model_editing
title: Text-to-Image Model Editing
- local: api/pipelines/stable_diffusion/diffedit
diff --git a/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx b/docs/source/en/api/pipelines/controlnet.mdx
similarity index 67%
rename from docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
rename to docs/source/en/api/pipelines/controlnet.mdx
index fd5c87821c01..f9e4c3c47e3e 100644
--- a/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
+++ b/docs/source/en/api/pipelines/controlnet.mdx
@@ -22,7 +22,7 @@ The abstract of the paper is the following:
*We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions. The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k). Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices. Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data. We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc. This may enrich the methods to control large diffusion models and further facilitate related applications.*
-This model was contributed by the amazing community contributor [takuma104](https://huggingface.co/takuma104) ❤️ .
+This model was contributed by the community contributor [takuma104](https://huggingface.co/takuma104) ❤️ .
Resources:
@@ -33,7 +33,9 @@ Resources:
| Pipeline | Tasks | Demo
|---|---|:---:|
-| [StableDiffusionControlNetPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py) | *Text-to-Image Generation with ControlNet Conditioning* | [Colab Example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb)
+| [StableDiffusionControlNetPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/controlnet/pipeline_controlnet.py) | *Text-to-Image Generation with ControlNet Conditioning* | [Colab Example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb)
+| [StableDiffusionControlNetImg2ImgPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/controlnet/pipeline_controlnet_img2img.py) | *Image-to-Image Generation with ControlNet Conditioning* |
+| [StableDiffusionControlNetInpaintPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_controlnet_inpaint.py) | *Inpainting Generation with ControlNet Conditioning* |
## Usage example
@@ -301,21 +303,22 @@ All checkpoints can be found under the authors' namespace [lllyasviel](https://h
### ControlNet v1.1
-| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
-|---|---|---|---|
-|[lllyasviel/control_v11p_sd15_canny](https://huggingface.co/lllyasviel/control_v11p_sd15_canny)
*Trained with canny edge detection* | A monochrome image with white edges on a black background.| |
| |
-|[lllyasviel/control_v11e_sd15_ip2p](https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p)
|
-|[lllyasviel/control_v11e_sd15_ip2p](https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p)
*Trained with pixel to pixel instruction* | No condition .| |
| |
-|[lllyasviel/control_v11p_sd15_inpaint](https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint)
|
-|[lllyasviel/control_v11p_sd15_inpaint](https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint)
Trained with image inpainting | No condition.| |
| |
-|[lllyasviel/control_v11p_sd15_mlsd](https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd)
|
-|[lllyasviel/control_v11p_sd15_mlsd](https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd)
Trained with multi-level line segment detection | An image with annotated line segments.| |
| |
-|[lllyasviel/control_v11f1p_sd15_depth](https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth)
|
-|[lllyasviel/control_v11f1p_sd15_depth](https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth)
Trained with depth estimation | An image with depth information, usually represented as a grayscale image.| |
| |
-|[lllyasviel/control_v11p_sd15_normalbae](https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae)
|
-|[lllyasviel/control_v11p_sd15_normalbae](https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae)
Trained with surface normal estimation | An image with surface normal information, usually represented as a color-coded image.| |
| |
-|[lllyasviel/control_v11p_sd15_seg](https://huggingface.co/lllyasviel/control_v11p_sd15_seg)
|
-|[lllyasviel/control_v11p_sd15_seg](https://huggingface.co/lllyasviel/control_v11p_sd15_seg)
Trained with image segmentation | An image with segmented regions, usually represented as a color-coded image.| |
| |
-|[lllyasviel/control_v11p_sd15_lineart](https://huggingface.co/lllyasviel/control_v11p_sd15_lineart)
|
-|[lllyasviel/control_v11p_sd15_lineart](https://huggingface.co/lllyasviel/control_v11p_sd15_lineart)
Trained with line art generation | An image with line art, usually black lines on a white background.| |
| |
-|[lllyasviel/control_v11p_sd15s2_lineart_anime](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)
|
-|[lllyasviel/control_v11p_sd15s2_lineart_anime](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)
Trained with anime line art generation | An image with anime-style line art.| |
| |
-|[lllyasviel/control_v11p_sd15_openpose](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)
|
-|[lllyasviel/control_v11p_sd15_openpose](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)
Trained with human pose estimation | An image with human poses, usually represented as a set of keypoints or skeletons.|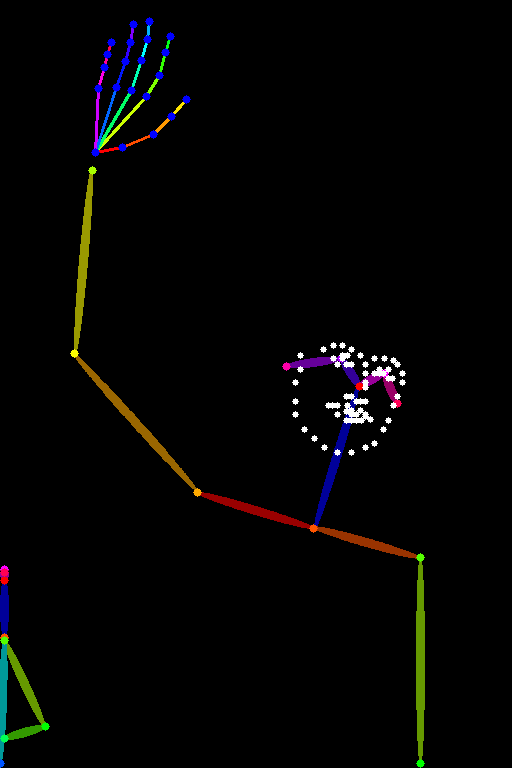 |
| |
-|[lllyasviel/control_v11p_sd15_scribble](https://huggingface.co/lllyasviel/control_v11p_sd15_scribble)
|
-|[lllyasviel/control_v11p_sd15_scribble](https://huggingface.co/lllyasviel/control_v11p_sd15_scribble)
Trained with scribble-based image generation | An image with scribbles, usually random or user-drawn strokes.| |
| |
-|[lllyasviel/control_v11p_sd15_softedge](https://huggingface.co/lllyasviel/control_v11p_sd15_softedge)
|
-|[lllyasviel/control_v11p_sd15_softedge](https://huggingface.co/lllyasviel/control_v11p_sd15_softedge)
Trained with soft edge image generation | An image with soft edges, usually to create a more painterly or artistic effect.| |
| |
-|[lllyasviel/control_v11e_sd15_shuffle](https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle)
|
-|[lllyasviel/control_v11e_sd15_shuffle](https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle)
Trained with image shuffling | An image with shuffled patches or regions.| |
| |
+| Model Name | Control Image Overview| Condition Image | Control Image Example | Generated Image Example |
+|---|---|---|---|---|
+|[lllyasviel/control_v11p_sd15_canny](https://huggingface.co/lllyasviel/control_v11p_sd15_canny)
|
+| Model Name | Control Image Overview| Condition Image | Control Image Example | Generated Image Example |
+|---|---|---|---|---|
+|[lllyasviel/control_v11p_sd15_canny](https://huggingface.co/lllyasviel/control_v11p_sd15_canny)
| *Trained with canny edge detection* | A monochrome image with white edges on a black background.|||
+|[lllyasviel/control_v11e_sd15_ip2p](https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p)
| *Trained with pixel to pixel instruction* | No condition .|||
+|[lllyasviel/control_v11p_sd15_inpaint](https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint)
| Trained with image inpainting | No condition.|||
+|[lllyasviel/control_v11p_sd15_mlsd](https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd)
| Trained with multi-level line segment detection | An image with annotated line segments.|||
+|[lllyasviel/control_v11f1p_sd15_depth](https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth)
| Trained with depth estimation | An image with depth information, usually represented as a grayscale image.|||
+|[lllyasviel/control_v11p_sd15_normalbae](https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae)
| Trained with surface normal estimation | An image with surface normal information, usually represented as a color-coded image.|||
+|[lllyasviel/control_v11p_sd15_seg](https://huggingface.co/lllyasviel/control_v11p_sd15_seg)
| Trained with image segmentation | An image with segmented regions, usually represented as a color-coded image.|||
+|[lllyasviel/control_v11p_sd15_lineart](https://huggingface.co/lllyasviel/control_v11p_sd15_lineart)
| Trained with line art generation | An image with line art, usually black lines on a white background.|||
+|[lllyasviel/control_v11p_sd15s2_lineart_anime](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)
| Trained with anime line art generation | An image with anime-style line art.|||
+|[lllyasviel/control_v11p_sd15_openpose](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)
| Trained with human pose estimation | An image with human poses, usually represented as a set of keypoints or skeletons.|||
+|[lllyasviel/control_v11p_sd15_scribble](https://huggingface.co/lllyasviel/control_v11p_sd15_scribble)
| Trained with scribble-based image generation | An image with scribbles, usually random or user-drawn strokes.|||
+|[lllyasviel/control_v11p_sd15_softedge](https://huggingface.co/lllyasviel/control_v11p_sd15_softedge)
| Trained with soft edge image generation | An image with soft edges, usually to create a more painterly or artistic effect.|||
+|[lllyasviel/control_v11e_sd15_shuffle](https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle)
| Trained with image shuffling | An image with shuffled patches or regions.|||
+|[lllyasviel/control_v11f1e_sd15_tile](https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile)
| Trained with image tiling | A blurry image or part of an image .| |
| |
## StableDiffusionControlNetPipeline
[[autodoc]] StableDiffusionControlNetPipeline
@@ -329,6 +332,30 @@ All checkpoints can be found under the authors' namespace [lllyasviel](https://h
- disable_xformers_memory_efficient_attention
- load_textual_inversion
+## StableDiffusionControlNetImg2ImgPipeline
+[[autodoc]] StableDiffusionControlNetImg2ImgPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+ - load_textual_inversion
+
+## StableDiffusionControlNetInpaintPipeline
+[[autodoc]] StableDiffusionControlNetInpaintPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+ - load_textual_inversion
+
## FlaxStableDiffusionControlNetPipeline
[[autodoc]] FlaxStableDiffusionControlNetPipeline
- all
diff --git a/docs/source/en/api/pipelines/overview.mdx b/docs/source/en/api/pipelines/overview.mdx
index 91716784f8fe..2b2f95590016 100644
--- a/docs/source/en/api/pipelines/overview.mdx
+++ b/docs/source/en/api/pipelines/overview.mdx
@@ -46,7 +46,7 @@ available a colab notebook to directly try them out.
|---|---|:---:|:---:|
| [alt_diffusion](./alt_diffusion) | [**AltDiffusion**](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation | -
| [audio_diffusion](./audio_diffusion) | [**Audio Diffusion**](https://github.com/teticio/audio_diffusion.git) | Unconditional Audio Generation |
-| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb)
+| [controlnet](./api/pipelines/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb)
| [cycle_diffusion](./cycle_diffusion) | [**Cycle Diffusion**](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
| [dance_diffusion](./dance_diffusion) | [**Dance Diffusion**](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
| [ddpm](./ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
diff --git a/docs/source/en/index.mdx b/docs/source/en/index.mdx
index 46a985ac2f8d..66548663827a 100644
--- a/docs/source/en/index.mdx
+++ b/docs/source/en/index.mdx
@@ -53,7 +53,7 @@ The library has three main components:
|---|---|:---:|
| [alt_diffusion](./api/pipelines/alt_diffusion) | [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
| [audio_diffusion](./api/pipelines/audio_diffusion) | [Audio Diffusion](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation |
-| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation |
+| [controlnet](./api/pipelines/controlnet) | [Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation |
| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
| [dance_diffusion](./api/pipelines/dance_diffusion) | [Dance Diffusion](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
| [ddpm](./api/pipelines/ddpm) | [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
diff --git a/src/diffusers/__init__.py b/src/diffusers/__init__.py
index a8293ea77fef..0d48a16b6216 100644
--- a/src/diffusers/__init__.py
+++ b/src/diffusers/__init__.py
@@ -132,6 +132,8 @@
PaintByExamplePipeline,
SemanticStableDiffusionPipeline,
StableDiffusionAttendAndExcitePipeline,
+ StableDiffusionControlNetImg2ImgPipeline,
+ StableDiffusionControlNetInpaintPipeline,
StableDiffusionControlNetPipeline,
StableDiffusionDepth2ImgPipeline,
StableDiffusionDiffEditPipeline,
diff --git a/src/diffusers/pipeline_utils.py b/src/diffusers/pipeline_utils.py
index 5c0c2337dc04..87709d5f616c 100644
--- a/src/diffusers/pipeline_utils.py
+++ b/src/diffusers/pipeline_utils.py
@@ -17,3 +17,13 @@
# It only exists so that temporarely `from diffusers.pipelines import DiffusionPipeline` works
from .pipelines import DiffusionPipeline, ImagePipelineOutput # noqa: F401
+from .utils import deprecate
+
+
+deprecate(
+ "pipelines_utils",
+ "0.22.0",
+ "Importing `DiffusionPipeline` or `ImagePipelineOutput` from diffusers.pipeline_utils is deprecated. Please import from diffusers.pipelines.pipeline_utils instead.",
+ standard_warn=False,
+ stacklevel=3,
+)
diff --git a/src/diffusers/pipelines/__init__.py b/src/diffusers/pipelines/__init__.py
index 3cddad4a6b26..9b44f4e5eb14 100644
--- a/src/diffusers/pipelines/__init__.py
+++ b/src/diffusers/pipelines/__init__.py
@@ -44,6 +44,11 @@
else:
from .alt_diffusion import AltDiffusionImg2ImgPipeline, AltDiffusionPipeline
from .audioldm import AudioLDMPipeline
+ from .controlnet import (
+ StableDiffusionControlNetImg2ImgPipeline,
+ StableDiffusionControlNetInpaintPipeline,
+ StableDiffusionControlNetPipeline,
+ )
from .deepfloyd_if import (
IFImg2ImgPipeline,
IFImg2ImgSuperResolutionPipeline,
@@ -58,7 +63,6 @@
from .stable_diffusion import (
CycleDiffusionPipeline,
StableDiffusionAttendAndExcitePipeline,
- StableDiffusionControlNetPipeline,
StableDiffusionDepth2ImgPipeline,
StableDiffusionDiffEditPipeline,
StableDiffusionImageVariationPipeline,
@@ -133,8 +137,8 @@
except OptionalDependencyNotAvailable:
from ..utils.dummy_flax_and_transformers_objects import * # noqa F403
else:
+ from .controlnet import FlaxStableDiffusionControlNetPipeline
from .stable_diffusion import (
- FlaxStableDiffusionControlNetPipeline,
FlaxStableDiffusionImg2ImgPipeline,
FlaxStableDiffusionInpaintPipeline,
FlaxStableDiffusionPipeline,
diff --git a/src/diffusers/pipelines/controlnet/__init__.py b/src/diffusers/pipelines/controlnet/__init__.py
new file mode 100644
index 000000000000..76ab63bdb116
--- /dev/null
+++ b/src/diffusers/pipelines/controlnet/__init__.py
@@ -0,0 +1,22 @@
+from ...utils import (
+ OptionalDependencyNotAvailable,
+ is_flax_available,
+ is_torch_available,
+ is_transformers_available,
+)
+
+
+try:
+ if not (is_transformers_available() and is_torch_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils.dummy_torch_and_transformers_objects import * # noqa F403
+else:
+ from .multicontrolnet import MultiControlNetModel
+ from .pipeline_controlnet import StableDiffusionControlNetPipeline
+ from .pipeline_controlnet_img2img import StableDiffusionControlNetImg2ImgPipeline
+ from .pipeline_controlnet_inpaint import StableDiffusionControlNetInpaintPipeline
+
+
+if is_transformers_available() and is_flax_available():
+ from .pipeline_flax_controlnet import FlaxStableDiffusionControlNetPipeline
diff --git a/src/diffusers/pipelines/controlnet/multicontrolnet.py b/src/diffusers/pipelines/controlnet/multicontrolnet.py
new file mode 100644
index 000000000000..91d40b20124c
--- /dev/null
+++ b/src/diffusers/pipelines/controlnet/multicontrolnet.py
@@ -0,0 +1,66 @@
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import torch
+from torch import nn
+
+from ...models.controlnet import ControlNetModel, ControlNetOutput
+from ...models.modeling_utils import ModelMixin
+
+
+class MultiControlNetModel(ModelMixin):
+ r"""
+ Multiple `ControlNetModel` wrapper class for Multi-ControlNet
+
+ This module is a wrapper for multiple instances of the `ControlNetModel`. The `forward()` API is designed to be
+ compatible with `ControlNetModel`.
+
+ Args:
+ controlnets (`List[ControlNetModel]`):
+ Provides additional conditioning to the unet during the denoising process. You must set multiple
+ `ControlNetModel` as a list.
+ """
+
+ def __init__(self, controlnets: Union[List[ControlNetModel], Tuple[ControlNetModel]]):
+ super().__init__()
+ self.nets = nn.ModuleList(controlnets)
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[torch.Tensor, float, int],
+ encoder_hidden_states: torch.Tensor,
+ controlnet_cond: List[torch.tensor],
+ conditioning_scale: List[float],
+ class_labels: Optional[torch.Tensor] = None,
+ timestep_cond: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guess_mode: bool = False,
+ return_dict: bool = True,
+ ) -> Union[ControlNetOutput, Tuple]:
+ for i, (image, scale, controlnet) in enumerate(zip(controlnet_cond, conditioning_scale, self.nets)):
+ down_samples, mid_sample = controlnet(
+ sample,
+ timestep,
+ encoder_hidden_states,
+ image,
+ scale,
+ class_labels,
+ timestep_cond,
+ attention_mask,
+ cross_attention_kwargs,
+ guess_mode,
+ return_dict,
+ )
+
+ # merge samples
+ if i == 0:
+ down_block_res_samples, mid_block_res_sample = down_samples, mid_sample
+ else:
+ down_block_res_samples = [
+ samples_prev + samples_curr
+ for samples_prev, samples_curr in zip(down_block_res_samples, down_samples)
+ ]
+ mid_block_res_sample += mid_sample
+
+ return down_block_res_samples, mid_block_res_sample
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet.py
new file mode 100644
index 000000000000..8a2ffbbff171
--- /dev/null
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet.py
@@ -0,0 +1,1035 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import inspect
+import os
+import warnings
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import PIL.Image
+import torch
+import torch.nn.functional as F
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...image_processor import VaeImageProcessor
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, ControlNetModel, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import (
+ PIL_INTERPOLATION,
+ is_accelerate_available,
+ is_accelerate_version,
+ is_compiled_module,
+ logging,
+ randn_tensor,
+ replace_example_docstring,
+)
+from ..pipeline_utils import DiffusionPipeline
+from ..stable_diffusion import StableDiffusionPipelineOutput
+from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
+from .multicontrolnet import MultiControlNetModel
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> # !pip install opencv-python transformers accelerate
+ >>> from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
+ >>> from diffusers.utils import load_image
+ >>> import numpy as np
+ >>> import torch
+
+ >>> import cv2
+ >>> from PIL import Image
+
+ >>> # download an image
+ >>> image = load_image(
+ ... "https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
+ ... )
+ >>> image = np.array(image)
+
+ >>> # get canny image
+ >>> image = cv2.Canny(image, 100, 200)
+ >>> image = image[:, :, None]
+ >>> image = np.concatenate([image, image, image], axis=2)
+ >>> canny_image = Image.fromarray(image)
+
+ >>> # load control net and stable diffusion v1-5
+ >>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
+ >>> pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
+ ... )
+
+ >>> # speed up diffusion process with faster scheduler and memory optimization
+ >>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+ >>> # remove following line if xformers is not installed
+ >>> pipe.enable_xformers_memory_efficient_attention()
+
+ >>> pipe.enable_model_cpu_offload()
+
+ >>> # generate image
+ >>> generator = torch.manual_seed(0)
+ >>> image = pipe(
+ ... "futuristic-looking woman", num_inference_steps=20, generator=generator, image=canny_image
+ ... ).images[0]
+ ```
+"""
+
+
+class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ In addition the pipeline inherits the following loading methods:
+ - *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
+ Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets
+ as a list, the outputs from each ControlNet are added together to create one combined additional
+ conditioning.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ if isinstance(controlnet, (list, tuple)):
+ controlnet = MultiControlNetModel(controlnet)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ controlnet=controlnet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
+ several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.controlnet]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ # the safety checker can offload the vae again
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # control net hook has be manually offloaded as it alternates with unet
+ cpu_offload_with_hook(self.controlnet, device)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is None:
+ has_nsfw_concept = None
+ else:
+ if torch.is_tensor(image):
+ feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
+ else:
+ feature_extractor_input = self.image_processor.numpy_to_pil(image)
+ safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ warnings.warn(
+ "The decode_latents method is deprecated and will be removed in a future version. Please"
+ " use VaeImageProcessor instead",
+ FutureWarning,
+ )
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents, return_dict=False)[0]
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ image,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ controlnet_conditioning_scale=1.0,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # `prompt` needs more sophisticated handling when there are multiple
+ # conditionings.
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if isinstance(prompt, list):
+ logger.warning(
+ f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
+ " prompts. The conditionings will be fixed across the prompts."
+ )
+
+ # Check `image`
+ is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
+ self.controlnet, torch._dynamo.eval_frame.OptimizedModule
+ )
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ self.check_image(image, prompt, prompt_embeds)
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if not isinstance(image, list):
+ raise TypeError("For multiple controlnets: `image` must be type `list`")
+
+ # When `image` is a nested list:
+ # (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
+ elif any(isinstance(i, list) for i in image):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif len(image) != len(self.controlnet.nets):
+ raise ValueError(
+ "For multiple controlnets: `image` must have the same length as the number of controlnets."
+ )
+
+ for image_ in image:
+ self.check_image(image_, prompt, prompt_embeds)
+ else:
+ assert False
+
+ # Check `controlnet_conditioning_scale`
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ if not isinstance(controlnet_conditioning_scale, float):
+ raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if isinstance(controlnet_conditioning_scale, list):
+ if any(isinstance(i, list) for i in controlnet_conditioning_scale):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
+ self.controlnet.nets
+ ):
+ raise ValueError(
+ "For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
+ " the same length as the number of controlnets"
+ )
+ else:
+ assert False
+
+ def check_image(self, image, prompt, prompt_embeds):
+ image_is_pil = isinstance(image, PIL.Image.Image)
+ image_is_tensor = isinstance(image, torch.Tensor)
+ image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
+ image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
+
+ if not image_is_pil and not image_is_tensor and not image_is_pil_list and not image_is_tensor_list:
+ raise TypeError(
+ "image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
+ )
+
+ if image_is_pil:
+ image_batch_size = 1
+ elif image_is_tensor:
+ image_batch_size = image.shape[0]
+ elif image_is_pil_list:
+ image_batch_size = len(image)
+ elif image_is_tensor_list:
+ image_batch_size = len(image)
+
+ if prompt is not None and isinstance(prompt, str):
+ prompt_batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ prompt_batch_size = len(prompt)
+ elif prompt_embeds is not None:
+ prompt_batch_size = prompt_embeds.shape[0]
+
+ if image_batch_size != 1 and image_batch_size != prompt_batch_size:
+ raise ValueError(
+ f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
+ )
+
+ def prepare_image(
+ self,
+ image,
+ width,
+ height,
+ batch_size,
+ num_images_per_prompt,
+ device,
+ dtype,
+ do_classifier_free_guidance=False,
+ guess_mode=False,
+ ):
+ if not isinstance(image, torch.Tensor):
+ if isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ images = []
+
+ for image_ in image:
+ image_ = image_.convert("RGB")
+ image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
+ image_ = np.array(image_)
+ image_ = image_[None, :]
+ images.append(image_)
+
+ image = images
+
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+
+ image_batch_size = image.shape[0]
+
+ if image_batch_size == 1:
+ repeat_by = batch_size
+ else:
+ # image batch size is the same as prompt batch size
+ repeat_by = num_images_per_prompt
+
+ image = image.repeat_interleave(repeat_by, dim=0)
+
+ image = image.to(device=device, dtype=dtype)
+
+ if do_classifier_free_guidance and not guess_mode:
+ image = torch.cat([image] * 2)
+
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ def _default_height_width(self, height, width, image):
+ # NOTE: It is possible that a list of images have different
+ # dimensions for each image, so just checking the first image
+ # is not _exactly_ correct, but it is simple.
+ while isinstance(image, list):
+ image = image[0]
+
+ if height is None:
+ if isinstance(image, PIL.Image.Image):
+ height = image.height
+ elif isinstance(image, torch.Tensor):
+ height = image.shape[2]
+
+ height = (height // 8) * 8 # round down to nearest multiple of 8
+
+ if width is None:
+ if isinstance(image, PIL.Image.Image):
+ width = image.width
+ elif isinstance(image, torch.Tensor):
+ width = image.shape[3]
+
+ width = (width // 8) * 8 # round down to nearest multiple of 8
+
+ return height, width
+
+ # override DiffusionPipeline
+ def save_pretrained(
+ self,
+ save_directory: Union[str, os.PathLike],
+ safe_serialization: bool = False,
+ variant: Optional[str] = None,
+ ):
+ if isinstance(self.controlnet, ControlNetModel):
+ super().save_pretrained(save_directory, safe_serialization, variant)
+ else:
+ raise NotImplementedError("Currently, the `save_pretrained()` is not implemented for Multi-ControlNet.")
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ image: Union[torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
+ guess_mode: bool = False,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`,
+ `List[List[torch.FloatTensor]]`, or `List[List[PIL.Image.Image]]`):
+ The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
+ the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
+ also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
+ height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
+ specified in init, images must be passed as a list such that each element of the list can be correctly
+ batched for input to a single controlnet.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+ controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
+ The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
+ to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
+ corresponding scale as a list.
+ guess_mode (`bool`, *optional*, defaults to `False`):
+ In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
+ you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height, width = self._default_height_width(height, width, image)
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ image,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ prompt_embeds,
+ negative_prompt_embeds,
+ controlnet_conditioning_scale,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
+
+ if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
+ controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
+
+ global_pool_conditions = (
+ controlnet.config.global_pool_conditions
+ if isinstance(controlnet, ControlNetModel)
+ else controlnet.nets[0].config.global_pool_conditions
+ )
+ guess_mode = guess_mode or global_pool_conditions
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare image
+ if isinstance(controlnet, ControlNetModel):
+ image = self.prepare_image(
+ image=image,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+ elif isinstance(controlnet, MultiControlNetModel):
+ images = []
+
+ for image_ in image:
+ image_ = self.prepare_image(
+ image=image_,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+
+ images.append(image_)
+
+ image = images
+ else:
+ assert False
+
+ # 5. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 6. Prepare latent variables
+ num_channels_latents = self.unet.config.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # controlnet(s) inference
+ if guess_mode and do_classifier_free_guidance:
+ # Infer ControlNet only for the conditional batch.
+ controlnet_latent_model_input = latents
+ controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
+ else:
+ controlnet_latent_model_input = latent_model_input
+ controlnet_prompt_embeds = prompt_embeds
+
+ down_block_res_samples, mid_block_res_sample = self.controlnet(
+ controlnet_latent_model_input,
+ t,
+ encoder_hidden_states=controlnet_prompt_embeds,
+ controlnet_cond=image,
+ conditioning_scale=controlnet_conditioning_scale,
+ guess_mode=guess_mode,
+ return_dict=False,
+ )
+
+ if guess_mode and do_classifier_free_guidance:
+ # Infered ControlNet only for the conditional batch.
+ # To apply the output of ControlNet to both the unconditional and conditional batches,
+ # add 0 to the unconditional batch to keep it unchanged.
+ down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
+ mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ down_block_additional_residuals=down_block_res_samples,
+ mid_block_additional_residual=mid_block_res_sample,
+ return_dict=False,
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # If we do sequential model offloading, let's offload unet and controlnet
+ # manually for max memory savings
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.unet.to("cpu")
+ self.controlnet.to("cpu")
+ torch.cuda.empty_cache()
+
+ if not output_type == "latent":
+ image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+ else:
+ image = latents
+ has_nsfw_concept = None
+
+ if has_nsfw_concept is None:
+ do_denormalize = [True] * image.shape[0]
+ else:
+ do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
+
+ image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet_img2img.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet_img2img.py
new file mode 100644
index 000000000000..cb5492790353
--- /dev/null
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet_img2img.py
@@ -0,0 +1,1113 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import inspect
+import os
+import warnings
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import PIL.Image
+import torch
+import torch.nn.functional as F
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...image_processor import VaeImageProcessor
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, ControlNetModel, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import (
+ PIL_INTERPOLATION,
+ deprecate,
+ is_accelerate_available,
+ is_accelerate_version,
+ is_compiled_module,
+ logging,
+ randn_tensor,
+ replace_example_docstring,
+)
+from ..pipeline_utils import DiffusionPipeline
+from ..stable_diffusion import StableDiffusionPipelineOutput
+from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
+from .multicontrolnet import MultiControlNetModel
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> # !pip install opencv-python transformers accelerate
+ >>> from diffusers import StableDiffusionControlNetImg2ImgPipeline, ControlNetModel, UniPCMultistepScheduler
+ >>> from diffusers.utils import load_image
+ >>> import numpy as np
+ >>> import torch
+
+ >>> import cv2
+ >>> from PIL import Image
+
+ >>> # download an image
+ >>> image = load_image(
+ ... "https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
+ ... )
+ >>> np_image = np.array(image)
+
+ >>> # get canny image
+ >>> np_image = cv2.Canny(np_image, 100, 200)
+ >>> np_image = np_image[:, :, None]
+ >>> np_image = np.concatenate([np_image, np_image, np_image], axis=2)
+ >>> canny_image = Image.fromarray(np_image)
+
+ >>> # load control net and stable diffusion v1-5
+ >>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
+ >>> pipe = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
+ ... )
+
+ >>> # speed up diffusion process with faster scheduler and memory optimization
+ >>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+ >>> pipe.enable_model_cpu_offload()
+
+ >>> # generate image
+ >>> generator = torch.manual_seed(0)
+ >>> image = pipe(
+ ... "futuristic-looking woman",
+ ... num_inference_steps=20,
+ ... generator=generator,
+ ... image=image,
+ ... control_image=canny_image,
+ ... ).images[0]
+ ```
+"""
+
+
+def prepare_image(image):
+ if isinstance(image, torch.Tensor):
+ # Batch single image
+ if image.ndim == 3:
+ image = image.unsqueeze(0)
+
+ image = image.to(dtype=torch.float32)
+ else:
+ # preprocess image
+ if isinstance(image, (PIL.Image.Image, np.ndarray)):
+ image = [image]
+
+ if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
+ image = [np.array(i.convert("RGB"))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ elif isinstance(image, list) and isinstance(image[0], np.ndarray):
+ image = np.concatenate([i[None, :] for i in image], axis=0)
+
+ image = image.transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
+
+ return image
+
+
+class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ In addition the pipeline inherits the following loading methods:
+ - *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
+ Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets
+ as a list, the outputs from each ControlNet are added together to create one combined additional
+ conditioning.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ if isinstance(controlnet, (list, tuple)):
+ controlnet = MultiControlNetModel(controlnet)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ controlnet=controlnet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
+ several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.controlnet]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ # the safety checker can offload the vae again
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # control net hook has be manually offloaded as it alternates with unet
+ cpu_offload_with_hook(self.controlnet, device)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is None:
+ has_nsfw_concept = None
+ else:
+ if torch.is_tensor(image):
+ feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
+ else:
+ feature_extractor_input = self.image_processor.numpy_to_pil(image)
+ safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ warnings.warn(
+ "The decode_latents method is deprecated and will be removed in a future version. Please"
+ " use VaeImageProcessor instead",
+ FutureWarning,
+ )
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents, return_dict=False)[0]
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ image,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ controlnet_conditioning_scale=1.0,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # `prompt` needs more sophisticated handling when there are multiple
+ # conditionings.
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if isinstance(prompt, list):
+ logger.warning(
+ f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
+ " prompts. The conditionings will be fixed across the prompts."
+ )
+
+ # Check `image`
+ is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
+ self.controlnet, torch._dynamo.eval_frame.OptimizedModule
+ )
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ self.check_image(image, prompt, prompt_embeds)
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if not isinstance(image, list):
+ raise TypeError("For multiple controlnets: `image` must be type `list`")
+
+ # When `image` is a nested list:
+ # (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
+ elif any(isinstance(i, list) for i in image):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif len(image) != len(self.controlnet.nets):
+ raise ValueError(
+ "For multiple controlnets: `image` must have the same length as the number of controlnets."
+ )
+
+ for image_ in image:
+ self.check_image(image_, prompt, prompt_embeds)
+ else:
+ assert False
+
+ # Check `controlnet_conditioning_scale`
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ if not isinstance(controlnet_conditioning_scale, float):
+ raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if isinstance(controlnet_conditioning_scale, list):
+ if any(isinstance(i, list) for i in controlnet_conditioning_scale):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
+ self.controlnet.nets
+ ):
+ raise ValueError(
+ "For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
+ " the same length as the number of controlnets"
+ )
+ else:
+ assert False
+
+ def check_image(self, image, prompt, prompt_embeds):
+ image_is_pil = isinstance(image, PIL.Image.Image)
+ image_is_tensor = isinstance(image, torch.Tensor)
+ image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
+ image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
+
+ if not image_is_pil and not image_is_tensor and not image_is_pil_list and not image_is_tensor_list:
+ raise TypeError(
+ "image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
+ )
+
+ if image_is_pil:
+ image_batch_size = 1
+ elif image_is_tensor:
+ image_batch_size = image.shape[0]
+ elif image_is_pil_list:
+ image_batch_size = len(image)
+ elif image_is_tensor_list:
+ image_batch_size = len(image)
+
+ if prompt is not None and isinstance(prompt, str):
+ prompt_batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ prompt_batch_size = len(prompt)
+ elif prompt_embeds is not None:
+ prompt_batch_size = prompt_embeds.shape[0]
+
+ if image_batch_size != 1 and image_batch_size != prompt_batch_size:
+ raise ValueError(
+ f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
+ )
+
+ # Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.prepare_image
+ def prepare_control_image(
+ self,
+ image,
+ width,
+ height,
+ batch_size,
+ num_images_per_prompt,
+ device,
+ dtype,
+ do_classifier_free_guidance=False,
+ guess_mode=False,
+ ):
+ if not isinstance(image, torch.Tensor):
+ if isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ images = []
+
+ for image_ in image:
+ image_ = image_.convert("RGB")
+ image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
+ image_ = np.array(image_)
+ image_ = image_[None, :]
+ images.append(image_)
+
+ image = images
+
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+
+ image_batch_size = image.shape[0]
+
+ if image_batch_size == 1:
+ repeat_by = batch_size
+ else:
+ # image batch size is the same as prompt batch size
+ repeat_by = num_images_per_prompt
+
+ image = image.repeat_interleave(repeat_by, dim=0)
+
+ image = image.to(device=device, dtype=dtype)
+
+ if do_classifier_free_guidance and not guess_mode:
+ image = torch.cat([image] * 2)
+
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.get_timesteps
+ def get_timesteps(self, num_inference_steps, strength, device):
+ # get the original timestep using init_timestep
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+
+ t_start = max(num_inference_steps - init_timestep, 0)
+ timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
+
+ return timesteps, num_inference_steps - t_start
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.prepare_latents
+ def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None):
+ if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
+ raise ValueError(
+ f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
+ )
+
+ image = image.to(device=device, dtype=dtype)
+
+ batch_size = batch_size * num_images_per_prompt
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if isinstance(generator, list):
+ init_latents = [
+ self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
+ ]
+ init_latents = torch.cat(init_latents, dim=0)
+ else:
+ init_latents = self.vae.encode(image).latent_dist.sample(generator)
+
+ init_latents = self.vae.config.scaling_factor * init_latents
+
+ if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
+ # expand init_latents for batch_size
+ deprecation_message = (
+ f"You have passed {batch_size} text prompts (`prompt`), but only {init_latents.shape[0]} initial"
+ " images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
+ " that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
+ " your script to pass as many initial images as text prompts to suppress this warning."
+ )
+ deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
+ additional_image_per_prompt = batch_size // init_latents.shape[0]
+ init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
+ elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
+ raise ValueError(
+ f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
+ )
+ else:
+ init_latents = torch.cat([init_latents], dim=0)
+
+ shape = init_latents.shape
+ noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+
+ # get latents
+ init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
+ latents = init_latents
+
+ return latents
+
+ def _default_height_width(self, height, width, image):
+ # NOTE: It is possible that a list of images have different
+ # dimensions for each image, so just checking the first image
+ # is not _exactly_ correct, but it is simple.
+ while isinstance(image, list):
+ image = image[0]
+
+ if height is None:
+ if isinstance(image, PIL.Image.Image):
+ height = image.height
+ elif isinstance(image, torch.Tensor):
+ height = image.shape[2]
+
+ height = (height // 8) * 8 # round down to nearest multiple of 8
+
+ if width is None:
+ if isinstance(image, PIL.Image.Image):
+ width = image.width
+ elif isinstance(image, torch.Tensor):
+ width = image.shape[3]
+
+ width = (width // 8) * 8 # round down to nearest multiple of 8
+
+ return height, width
+
+ # override DiffusionPipeline
+ def save_pretrained(
+ self,
+ save_directory: Union[str, os.PathLike],
+ safe_serialization: bool = False,
+ variant: Optional[str] = None,
+ ):
+ if isinstance(self.controlnet, ControlNetModel):
+ super().save_pretrained(save_directory, safe_serialization, variant)
+ else:
+ raise NotImplementedError("Currently, the `save_pretrained()` is not implemented for Multi-ControlNet.")
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ image: Union[torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]] = None,
+ control_image: Union[
+ torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]
+ ] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ strength: float = 0.8,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ controlnet_conditioning_scale: Union[float, List[float]] = 0.8,
+ guess_mode: bool = False,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`,
+ `List[List[torch.FloatTensor]]`, or `List[List[PIL.Image.Image]]`):
+ The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
+ the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
+ also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
+ height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
+ specified in init, images must be passed as a list such that each element of the list can be correctly
+ batched for input to a single controlnet.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+ controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
+ The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
+ to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
+ corresponding scale as a list. Note that by default, we use a smaller conditioning scale for inpainting
+ than for [`~StableDiffusionControlNetPipeline.__call__`].
+ guess_mode (`bool`, *optional*, defaults to `False`):
+ In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
+ you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height, width = self._default_height_width(height, width, image)
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ control_image,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ prompt_embeds,
+ negative_prompt_embeds,
+ controlnet_conditioning_scale,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
+
+ if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
+ controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
+
+ global_pool_conditions = (
+ controlnet.config.global_pool_conditions
+ if isinstance(controlnet, ControlNetModel)
+ else controlnet.nets[0].config.global_pool_conditions
+ )
+ guess_mode = guess_mode or global_pool_conditions
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+ # 4. Prepare image, and controlnet_conditioning_image
+ image = prepare_image(image)
+
+ # 5. Prepare image
+ if isinstance(controlnet, ControlNetModel):
+ control_image = self.prepare_control_image(
+ image=control_image,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+ elif isinstance(controlnet, MultiControlNetModel):
+ control_images = []
+
+ for control_image_ in control_image:
+ control_image_ = self.prepare_control_image(
+ image=control_image_,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+
+ control_images.append(control_image_)
+
+ control_image = control_images
+ else:
+ assert False
+
+ # 5. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
+ latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
+
+ # 6. Prepare latent variables
+ latents = self.prepare_latents(
+ image,
+ latent_timestep,
+ batch_size,
+ num_images_per_prompt,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # controlnet(s) inference
+ if guess_mode and do_classifier_free_guidance:
+ # Infer ControlNet only for the conditional batch.
+ controlnet_latent_model_input = latents
+ controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
+ else:
+ controlnet_latent_model_input = latent_model_input
+ controlnet_prompt_embeds = prompt_embeds
+
+ down_block_res_samples, mid_block_res_sample = self.controlnet(
+ controlnet_latent_model_input,
+ t,
+ encoder_hidden_states=controlnet_prompt_embeds,
+ controlnet_cond=control_image,
+ conditioning_scale=controlnet_conditioning_scale,
+ guess_mode=guess_mode,
+ return_dict=False,
+ )
+
+ if guess_mode and do_classifier_free_guidance:
+ # Infered ControlNet only for the conditional batch.
+ # To apply the output of ControlNet to both the unconditional and conditional batches,
+ # add 0 to the unconditional batch to keep it unchanged.
+ down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
+ mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ down_block_additional_residuals=down_block_res_samples,
+ mid_block_additional_residual=mid_block_res_sample,
+ return_dict=False,
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # If we do sequential model offloading, let's offload unet and controlnet
+ # manually for max memory savings
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.unet.to("cpu")
+ self.controlnet.to("cpu")
+ torch.cuda.empty_cache()
+
+ if not output_type == "latent":
+ image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+ else:
+ image = latents
+ has_nsfw_concept = None
+
+ if has_nsfw_concept is None:
+ do_denormalize = [True] * image.shape[0]
+ else:
+ do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
+
+ image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint.py
new file mode 100644
index 000000000000..a146a1cc2908
--- /dev/null
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint.py
@@ -0,0 +1,1228 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This model implementation is heavily inspired by https://github.com/haofanwang/ControlNet-for-Diffusers/
+
+import inspect
+import os
+import warnings
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import PIL.Image
+import torch
+import torch.nn.functional as F
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...image_processor import VaeImageProcessor
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, ControlNetModel, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import (
+ PIL_INTERPOLATION,
+ is_accelerate_available,
+ is_accelerate_version,
+ is_compiled_module,
+ logging,
+ randn_tensor,
+ replace_example_docstring,
+)
+from ..pipeline_utils import DiffusionPipeline
+from ..stable_diffusion import StableDiffusionPipelineOutput
+from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
+from .multicontrolnet import MultiControlNetModel
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> # !pip install opencv-python transformers accelerate
+ >>> from diffusers import StableDiffusionControlNetInpaintPipeline, ControlNetModel, UniPCMultistepScheduler
+ >>> from diffusers.utils import load_image
+ >>> import numpy as np
+ >>> import torch
+
+ >>> import cv2
+ >>> from PIL import Image
+
+ >>> img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
+ >>> mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
+
+ >>> init_image = load_image(img_url).resize((512, 512))
+ >>> mask_image = load_image(mask_url).resize((512, 512))
+
+ >>> image = np.array(init_image)
+
+ >>> # get canny image
+ >>> image = cv2.Canny(image, 100, 200)
+ >>> image = image[:, :, None]
+ >>> image = np.concatenate([image, image, image], axis=2)
+ >>> canny_image = Image.fromarray(image)
+
+ >>> # load control net and stable diffusion inpainting
+ >>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
+ >>> pipe = StableDiffusionControlNetInpaintPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-inpainting", controlnet=controlnet, torch_dtype=torch.float16
+ ... )
+
+ >>> # speed up diffusion process with faster scheduler and memory optimization
+ >>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+
+ >>> pipe.enable_model_cpu_offload()
+
+ >>> # generate image
+ >>> generator = torch.manual_seed(0)
+ >>> image = pipe(
+ ... "spiderman",
+ ... num_inference_steps=30,
+ ... generator=generator,
+ ... image=init_image,
+ ... mask_image=mask_image,
+ ... control_image=canny_image,
+ ... ).images[0]
+ ```
+"""
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint.prepare_mask_and_masked_image
+def prepare_mask_and_masked_image(image, mask, height, width):
+ """
+ Prepares a pair (image, mask) to be consumed by the Stable Diffusion pipeline. This means that those inputs will be
+ converted to ``torch.Tensor`` with shapes ``batch x channels x height x width`` where ``channels`` is ``3`` for the
+ ``image`` and ``1`` for the ``mask``.
+
+ The ``image`` will be converted to ``torch.float32`` and normalized to be in ``[-1, 1]``. The ``mask`` will be
+ binarized (``mask > 0.5``) and cast to ``torch.float32`` too.
+
+ Args:
+ image (Union[np.array, PIL.Image, torch.Tensor]): The image to inpaint.
+ It can be a ``PIL.Image``, or a ``height x width x 3`` ``np.array`` or a ``channels x height x width``
+ ``torch.Tensor`` or a ``batch x channels x height x width`` ``torch.Tensor``.
+ mask (_type_): The mask to apply to the image, i.e. regions to inpaint.
+ It can be a ``PIL.Image``, or a ``height x width`` ``np.array`` or a ``1 x height x width``
+ ``torch.Tensor`` or a ``batch x 1 x height x width`` ``torch.Tensor``.
+
+
+ Raises:
+ ValueError: ``torch.Tensor`` images should be in the ``[-1, 1]`` range. ValueError: ``torch.Tensor`` mask
+ should be in the ``[0, 1]`` range. ValueError: ``mask`` and ``image`` should have the same spatial dimensions.
+ TypeError: ``mask`` is a ``torch.Tensor`` but ``image`` is not
+ (ot the other way around).
+
+ Returns:
+ tuple[torch.Tensor]: The pair (mask, masked_image) as ``torch.Tensor`` with 4
+ dimensions: ``batch x channels x height x width``.
+ """
+
+ if image is None:
+ raise ValueError("`image` input cannot be undefined.")
+
+ if mask is None:
+ raise ValueError("`mask_image` input cannot be undefined.")
+
+ if isinstance(image, torch.Tensor):
+ if not isinstance(mask, torch.Tensor):
+ raise TypeError(f"`image` is a torch.Tensor but `mask` (type: {type(mask)} is not")
+
+ # Batch single image
+ if image.ndim == 3:
+ assert image.shape[0] == 3, "Image outside a batch should be of shape (3, H, W)"
+ image = image.unsqueeze(0)
+
+ # Batch and add channel dim for single mask
+ if mask.ndim == 2:
+ mask = mask.unsqueeze(0).unsqueeze(0)
+
+ # Batch single mask or add channel dim
+ if mask.ndim == 3:
+ # Single batched mask, no channel dim or single mask not batched but channel dim
+ if mask.shape[0] == 1:
+ mask = mask.unsqueeze(0)
+
+ # Batched masks no channel dim
+ else:
+ mask = mask.unsqueeze(1)
+
+ assert image.ndim == 4 and mask.ndim == 4, "Image and Mask must have 4 dimensions"
+ assert image.shape[-2:] == mask.shape[-2:], "Image and Mask must have the same spatial dimensions"
+ assert image.shape[0] == mask.shape[0], "Image and Mask must have the same batch size"
+
+ # Check image is in [-1, 1]
+ if image.min() < -1 or image.max() > 1:
+ raise ValueError("Image should be in [-1, 1] range")
+
+ # Check mask is in [0, 1]
+ if mask.min() < 0 or mask.max() > 1:
+ raise ValueError("Mask should be in [0, 1] range")
+
+ # Binarize mask
+ mask[mask < 0.5] = 0
+ mask[mask >= 0.5] = 1
+
+ # Image as float32
+ image = image.to(dtype=torch.float32)
+ elif isinstance(mask, torch.Tensor):
+ raise TypeError(f"`mask` is a torch.Tensor but `image` (type: {type(image)} is not")
+ else:
+ # preprocess image
+ if isinstance(image, (PIL.Image.Image, np.ndarray)):
+ image = [image]
+ if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
+ # resize all images w.r.t passed height an width
+ image = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in image]
+ image = [np.array(i.convert("RGB"))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ elif isinstance(image, list) and isinstance(image[0], np.ndarray):
+ image = np.concatenate([i[None, :] for i in image], axis=0)
+
+ image = image.transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
+
+ # preprocess mask
+ if isinstance(mask, (PIL.Image.Image, np.ndarray)):
+ mask = [mask]
+
+ if isinstance(mask, list) and isinstance(mask[0], PIL.Image.Image):
+ mask = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in mask]
+ mask = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask], axis=0)
+ mask = mask.astype(np.float32) / 255.0
+ elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
+ mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
+
+ mask[mask < 0.5] = 0
+ mask[mask >= 0.5] = 1
+ mask = torch.from_numpy(mask)
+
+ masked_image = image * (mask < 0.5)
+
+ return mask, masked_image
+
+
+class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ In addition the pipeline inherits the following loading methods:
+ - *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
+ Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets
+ as a list, the outputs from each ControlNet are added together to create one combined additional
+ conditioning.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ if isinstance(controlnet, (list, tuple)):
+ controlnet = MultiControlNetModel(controlnet)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ controlnet=controlnet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
+ several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.controlnet]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ # the safety checker can offload the vae again
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # control net hook has be manually offloaded as it alternates with unet
+ cpu_offload_with_hook(self.controlnet, device)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is None:
+ has_nsfw_concept = None
+ else:
+ if torch.is_tensor(image):
+ feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
+ else:
+ feature_extractor_input = self.image_processor.numpy_to_pil(image)
+ safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ warnings.warn(
+ "The decode_latents method is deprecated and will be removed in a future version. Please"
+ " use VaeImageProcessor instead",
+ FutureWarning,
+ )
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents, return_dict=False)[0]
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ image,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ controlnet_conditioning_scale=1.0,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # `prompt` needs more sophisticated handling when there are multiple
+ # conditionings.
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if isinstance(prompt, list):
+ logger.warning(
+ f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
+ " prompts. The conditionings will be fixed across the prompts."
+ )
+
+ # Check `image`
+ is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
+ self.controlnet, torch._dynamo.eval_frame.OptimizedModule
+ )
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ self.check_image(image, prompt, prompt_embeds)
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if not isinstance(image, list):
+ raise TypeError("For multiple controlnets: `image` must be type `list`")
+
+ # When `image` is a nested list:
+ # (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
+ elif any(isinstance(i, list) for i in image):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif len(image) != len(self.controlnet.nets):
+ raise ValueError(
+ "For multiple controlnets: `image` must have the same length as the number of controlnets."
+ )
+
+ for image_ in image:
+ self.check_image(image_, prompt, prompt_embeds)
+ else:
+ assert False
+
+ # Check `controlnet_conditioning_scale`
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ if not isinstance(controlnet_conditioning_scale, float):
+ raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if isinstance(controlnet_conditioning_scale, list):
+ if any(isinstance(i, list) for i in controlnet_conditioning_scale):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
+ self.controlnet.nets
+ ):
+ raise ValueError(
+ "For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
+ " the same length as the number of controlnets"
+ )
+ else:
+ assert False
+
+ def check_image(self, image, prompt, prompt_embeds):
+ image_is_pil = isinstance(image, PIL.Image.Image)
+ image_is_tensor = isinstance(image, torch.Tensor)
+ image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
+ image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
+
+ if not image_is_pil and not image_is_tensor and not image_is_pil_list and not image_is_tensor_list:
+ raise TypeError(
+ "image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
+ )
+
+ if image_is_pil:
+ image_batch_size = 1
+ elif image_is_tensor:
+ image_batch_size = image.shape[0]
+ elif image_is_pil_list:
+ image_batch_size = len(image)
+ elif image_is_tensor_list:
+ image_batch_size = len(image)
+
+ if prompt is not None and isinstance(prompt, str):
+ prompt_batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ prompt_batch_size = len(prompt)
+ elif prompt_embeds is not None:
+ prompt_batch_size = prompt_embeds.shape[0]
+
+ if image_batch_size != 1 and image_batch_size != prompt_batch_size:
+ raise ValueError(
+ f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
+ )
+
+ # Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.prepare_image
+ def prepare_control_image(
+ self,
+ image,
+ width,
+ height,
+ batch_size,
+ num_images_per_prompt,
+ device,
+ dtype,
+ do_classifier_free_guidance=False,
+ guess_mode=False,
+ ):
+ if not isinstance(image, torch.Tensor):
+ if isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ images = []
+
+ for image_ in image:
+ image_ = image_.convert("RGB")
+ image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
+ image_ = np.array(image_)
+ image_ = image_[None, :]
+ images.append(image_)
+
+ image = images
+
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+
+ image_batch_size = image.shape[0]
+
+ if image_batch_size == 1:
+ repeat_by = batch_size
+ else:
+ # image batch size is the same as prompt batch size
+ repeat_by = num_images_per_prompt
+
+ image = image.repeat_interleave(repeat_by, dim=0)
+
+ image = image.to(device=device, dtype=dtype)
+
+ if do_classifier_free_guidance and not guess_mode:
+ image = torch.cat([image] * 2)
+
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint.StableDiffusionInpaintPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ def _default_height_width(self, height, width, image):
+ # NOTE: It is possible that a list of images have different
+ # dimensions for each image, so just checking the first image
+ # is not _exactly_ correct, but it is simple.
+ while isinstance(image, list):
+ image = image[0]
+
+ if height is None:
+ if isinstance(image, PIL.Image.Image):
+ height = image.height
+ elif isinstance(image, torch.Tensor):
+ height = image.shape[2]
+
+ height = (height // 8) * 8 # round down to nearest multiple of 8
+
+ if width is None:
+ if isinstance(image, PIL.Image.Image):
+ width = image.width
+ elif isinstance(image, torch.Tensor):
+ width = image.shape[3]
+
+ width = (width // 8) * 8 # round down to nearest multiple of 8
+
+ return height, width
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint.StableDiffusionInpaintPipeline.prepare_mask_latents
+ def prepare_mask_latents(
+ self, mask, masked_image, batch_size, height, width, dtype, device, generator, do_classifier_free_guidance
+ ):
+ # resize the mask to latents shape as we concatenate the mask to the latents
+ # we do that before converting to dtype to avoid breaking in case we're using cpu_offload
+ # and half precision
+ mask = torch.nn.functional.interpolate(
+ mask, size=(height // self.vae_scale_factor, width // self.vae_scale_factor)
+ )
+ mask = mask.to(device=device, dtype=dtype)
+
+ masked_image = masked_image.to(device=device, dtype=dtype)
+
+ # encode the mask image into latents space so we can concatenate it to the latents
+ if isinstance(generator, list):
+ masked_image_latents = [
+ self.vae.encode(masked_image[i : i + 1]).latent_dist.sample(generator=generator[i])
+ for i in range(batch_size)
+ ]
+ masked_image_latents = torch.cat(masked_image_latents, dim=0)
+ else:
+ masked_image_latents = self.vae.encode(masked_image).latent_dist.sample(generator=generator)
+ masked_image_latents = self.vae.config.scaling_factor * masked_image_latents
+
+ # duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
+ if mask.shape[0] < batch_size:
+ if not batch_size % mask.shape[0] == 0:
+ raise ValueError(
+ "The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
+ f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
+ " of masks that you pass is divisible by the total requested batch size."
+ )
+ mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
+ if masked_image_latents.shape[0] < batch_size:
+ if not batch_size % masked_image_latents.shape[0] == 0:
+ raise ValueError(
+ "The passed images and the required batch size don't match. Images are supposed to be duplicated"
+ f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
+ " Make sure the number of images that you pass is divisible by the total requested batch size."
+ )
+ masked_image_latents = masked_image_latents.repeat(batch_size // masked_image_latents.shape[0], 1, 1, 1)
+
+ mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
+ masked_image_latents = (
+ torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
+ )
+
+ # aligning device to prevent device errors when concating it with the latent model input
+ masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
+ return mask, masked_image_latents
+
+ # override DiffusionPipeline
+ def save_pretrained(
+ self,
+ save_directory: Union[str, os.PathLike],
+ safe_serialization: bool = False,
+ variant: Optional[str] = None,
+ ):
+ if isinstance(self.controlnet, ControlNetModel):
+ super().save_pretrained(save_directory, safe_serialization, variant)
+ else:
+ raise NotImplementedError("Currently, the `save_pretrained()` is not implemented for Multi-ControlNet.")
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ image: Union[torch.Tensor, PIL.Image.Image] = None,
+ mask_image: Union[torch.Tensor, PIL.Image.Image] = None,
+ control_image: Union[
+ torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]
+ ] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ controlnet_conditioning_scale: Union[float, List[float]] = 0.5,
+ guess_mode: bool = False,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`,
+ `List[List[torch.FloatTensor]]`, or `List[List[PIL.Image.Image]]`):
+ The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
+ the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
+ also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
+ height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
+ specified in init, images must be passed as a list such that each element of the list can be correctly
+ batched for input to a single controlnet.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+ controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 0.5):
+ The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
+ to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
+ corresponding scale as a list. Note that by default, we use a smaller conditioning scale for inpainting
+ than for [`~StableDiffusionControlNetPipeline.__call__`].
+ guess_mode (`bool`, *optional*, defaults to `False`):
+ In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
+ you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height, width = self._default_height_width(height, width, image)
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ control_image,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ prompt_embeds,
+ negative_prompt_embeds,
+ controlnet_conditioning_scale,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
+
+ if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
+ controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
+
+ global_pool_conditions = (
+ controlnet.config.global_pool_conditions
+ if isinstance(controlnet, ControlNetModel)
+ else controlnet.nets[0].config.global_pool_conditions
+ )
+ guess_mode = guess_mode or global_pool_conditions
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare image
+ if isinstance(controlnet, ControlNetModel):
+ control_image = self.prepare_control_image(
+ image=control_image,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+ elif isinstance(controlnet, MultiControlNetModel):
+ control_images = []
+
+ for control_image_ in control_image:
+ control_image_ = self.prepare_control_image(
+ image=control_image_,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+
+ control_images.append(control_image_)
+
+ control_image = control_images
+ else:
+ assert False
+
+ # 4. Preprocess mask and image - resizes image and mask w.r.t height and width
+ # 5. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 6. Prepare latent variables
+ num_channels_latents = self.vae.config.latent_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Prepare mask latent variables
+ mask, masked_image = prepare_mask_and_masked_image(image, mask_image, height, width)
+ mask, masked_image_latents = self.prepare_mask_latents(
+ mask,
+ masked_image,
+ batch_size * num_images_per_prompt,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ do_classifier_free_guidance,
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ if guess_mode and do_classifier_free_guidance:
+ # Infer ControlNet only for the conditional batch.
+ controlnet_latent_model_input = latents
+ controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
+ else:
+ controlnet_latent_model_input = latent_model_input
+ controlnet_prompt_embeds = prompt_embeds
+
+ down_block_res_samples, mid_block_res_sample = self.controlnet(
+ controlnet_latent_model_input,
+ t,
+ encoder_hidden_states=controlnet_prompt_embeds,
+ controlnet_cond=control_image,
+ conditioning_scale=controlnet_conditioning_scale,
+ guess_mode=guess_mode,
+ return_dict=False,
+ )
+
+ if guess_mode and do_classifier_free_guidance:
+ # Infered ControlNet only for the conditional batch.
+ # To apply the output of ControlNet to both the unconditional and conditional batches,
+ # add 0 to the unconditional batch to keep it unchanged.
+ down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
+ mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
+
+ # predict the noise residual
+ latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ down_block_additional_residuals=down_block_res_samples,
+ mid_block_additional_residual=mid_block_res_sample,
+ return_dict=False,
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # If we do sequential model offloading, let's offload unet and controlnet
+ # manually for max memory savings
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.unet.to("cpu")
+ self.controlnet.to("cpu")
+ torch.cuda.empty_cache()
+
+ if not output_type == "latent":
+ image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+ else:
+ image = latents
+ has_nsfw_concept = None
+
+ if has_nsfw_concept is None:
+ do_denormalize = [True] * image.shape[0]
+ else:
+ do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
+
+ image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/src/diffusers/pipelines/controlnet/pipeline_flax_controlnet.py b/src/diffusers/pipelines/controlnet/pipeline_flax_controlnet.py
new file mode 100644
index 000000000000..6003fc96b0ad
--- /dev/null
+++ b/src/diffusers/pipelines/controlnet/pipeline_flax_controlnet.py
@@ -0,0 +1,537 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import warnings
+from functools import partial
+from typing import Dict, List, Optional, Union
+
+import jax
+import jax.numpy as jnp
+import numpy as np
+from flax.core.frozen_dict import FrozenDict
+from flax.jax_utils import unreplicate
+from flax.training.common_utils import shard
+from PIL import Image
+from transformers import CLIPFeatureExtractor, CLIPTokenizer, FlaxCLIPTextModel
+
+from ...models import FlaxAutoencoderKL, FlaxControlNetModel, FlaxUNet2DConditionModel
+from ...schedulers import (
+ FlaxDDIMScheduler,
+ FlaxDPMSolverMultistepScheduler,
+ FlaxLMSDiscreteScheduler,
+ FlaxPNDMScheduler,
+)
+from ...utils import PIL_INTERPOLATION, logging, replace_example_docstring
+from ..pipeline_flax_utils import FlaxDiffusionPipeline
+from ..stable_diffusion import FlaxStableDiffusionPipelineOutput
+from ..stable_diffusion.safety_checker_flax import FlaxStableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+# Set to True to use python for loop instead of jax.fori_loop for easier debugging
+DEBUG = False
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import jax
+ >>> import numpy as np
+ >>> import jax.numpy as jnp
+ >>> from flax.jax_utils import replicate
+ >>> from flax.training.common_utils import shard
+ >>> from diffusers.utils import load_image
+ >>> from PIL import Image
+ >>> from diffusers import FlaxStableDiffusionControlNetPipeline, FlaxControlNetModel
+
+
+ >>> def image_grid(imgs, rows, cols):
+ ... w, h = imgs[0].size
+ ... grid = Image.new("RGB", size=(cols * w, rows * h))
+ ... for i, img in enumerate(imgs):
+ ... grid.paste(img, box=(i % cols * w, i // cols * h))
+ ... return grid
+
+
+ >>> def create_key(seed=0):
+ ... return jax.random.PRNGKey(seed)
+
+
+ >>> rng = create_key(0)
+
+ >>> # get canny image
+ >>> canny_image = load_image(
+ ... "https://huggingface.co/datasets/YiYiXu/test-doc-assets/resolve/main/blog_post_cell_10_output_0.jpeg"
+ ... )
+
+ >>> prompts = "best quality, extremely detailed"
+ >>> negative_prompts = "monochrome, lowres, bad anatomy, worst quality, low quality"
+
+ >>> # load control net and stable diffusion v1-5
+ >>> controlnet, controlnet_params = FlaxControlNetModel.from_pretrained(
+ ... "lllyasviel/sd-controlnet-canny", from_pt=True, dtype=jnp.float32
+ ... )
+ >>> pipe, params = FlaxStableDiffusionControlNetPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, revision="flax", dtype=jnp.float32
+ ... )
+ >>> params["controlnet"] = controlnet_params
+
+ >>> num_samples = jax.device_count()
+ >>> rng = jax.random.split(rng, jax.device_count())
+
+ >>> prompt_ids = pipe.prepare_text_inputs([prompts] * num_samples)
+ >>> negative_prompt_ids = pipe.prepare_text_inputs([negative_prompts] * num_samples)
+ >>> processed_image = pipe.prepare_image_inputs([canny_image] * num_samples)
+
+ >>> p_params = replicate(params)
+ >>> prompt_ids = shard(prompt_ids)
+ >>> negative_prompt_ids = shard(negative_prompt_ids)
+ >>> processed_image = shard(processed_image)
+
+ >>> output = pipe(
+ ... prompt_ids=prompt_ids,
+ ... image=processed_image,
+ ... params=p_params,
+ ... prng_seed=rng,
+ ... num_inference_steps=50,
+ ... neg_prompt_ids=negative_prompt_ids,
+ ... jit=True,
+ ... ).images
+
+ >>> output_images = pipe.numpy_to_pil(np.asarray(output.reshape((num_samples,) + output.shape[-3:])))
+ >>> output_images = image_grid(output_images, num_samples // 4, 4)
+ >>> output_images.save("generated_image.png")
+ ```
+"""
+
+
+class FlaxStableDiffusionControlNetPipeline(FlaxDiffusionPipeline):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion with ControlNet Guidance.
+
+ This model inherits from [`FlaxDiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`FlaxAutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`FlaxCLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.FlaxCLIPTextModel),
+ specifically the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`FlaxUNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ controlnet ([`FlaxControlNetModel`]:
+ Provides additional conditioning to the unet during the denoising process.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`FlaxDDIMScheduler`], [`FlaxLMSDiscreteScheduler`], [`FlaxPNDMScheduler`], or
+ [`FlaxDPMSolverMultistepScheduler`].
+ safety_checker ([`FlaxStableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPFeatureExtractor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+
+ def __init__(
+ self,
+ vae: FlaxAutoencoderKL,
+ text_encoder: FlaxCLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: FlaxUNet2DConditionModel,
+ controlnet: FlaxControlNetModel,
+ scheduler: Union[
+ FlaxDDIMScheduler, FlaxPNDMScheduler, FlaxLMSDiscreteScheduler, FlaxDPMSolverMultistepScheduler
+ ],
+ safety_checker: FlaxStableDiffusionSafetyChecker,
+ feature_extractor: CLIPFeatureExtractor,
+ dtype: jnp.dtype = jnp.float32,
+ ):
+ super().__init__()
+ self.dtype = dtype
+
+ if safety_checker is None:
+ logger.warn(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ controlnet=controlnet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ def prepare_text_inputs(self, prompt: Union[str, List[str]]):
+ if not isinstance(prompt, (str, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ text_input = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+
+ return text_input.input_ids
+
+ def prepare_image_inputs(self, image: Union[Image.Image, List[Image.Image]]):
+ if not isinstance(image, (Image.Image, list)):
+ raise ValueError(f"image has to be of type `PIL.Image.Image` or list but is {type(image)}")
+
+ if isinstance(image, Image.Image):
+ image = [image]
+
+ processed_images = jnp.concatenate([preprocess(img, jnp.float32) for img in image])
+
+ return processed_images
+
+ def _get_has_nsfw_concepts(self, features, params):
+ has_nsfw_concepts = self.safety_checker(features, params)
+ return has_nsfw_concepts
+
+ def _run_safety_checker(self, images, safety_model_params, jit=False):
+ # safety_model_params should already be replicated when jit is True
+ pil_images = [Image.fromarray(image) for image in images]
+ features = self.feature_extractor(pil_images, return_tensors="np").pixel_values
+
+ if jit:
+ features = shard(features)
+ has_nsfw_concepts = _p_get_has_nsfw_concepts(self, features, safety_model_params)
+ has_nsfw_concepts = unshard(has_nsfw_concepts)
+ safety_model_params = unreplicate(safety_model_params)
+ else:
+ has_nsfw_concepts = self._get_has_nsfw_concepts(features, safety_model_params)
+
+ images_was_copied = False
+ for idx, has_nsfw_concept in enumerate(has_nsfw_concepts):
+ if has_nsfw_concept:
+ if not images_was_copied:
+ images_was_copied = True
+ images = images.copy()
+
+ images[idx] = np.zeros(images[idx].shape, dtype=np.uint8) # black image
+
+ if any(has_nsfw_concepts):
+ warnings.warn(
+ "Potential NSFW content was detected in one or more images. A black image will be returned"
+ " instead. Try again with a different prompt and/or seed."
+ )
+
+ return images, has_nsfw_concepts
+
+ def _generate(
+ self,
+ prompt_ids: jnp.array,
+ image: jnp.array,
+ params: Union[Dict, FrozenDict],
+ prng_seed: jax.random.KeyArray,
+ num_inference_steps: int,
+ guidance_scale: float,
+ latents: Optional[jnp.array] = None,
+ neg_prompt_ids: Optional[jnp.array] = None,
+ controlnet_conditioning_scale: float = 1.0,
+ ):
+ height, width = image.shape[-2:]
+ if height % 64 != 0 or width % 64 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 64 but are {height} and {width}.")
+
+ # get prompt text embeddings
+ prompt_embeds = self.text_encoder(prompt_ids, params=params["text_encoder"])[0]
+
+ # TODO: currently it is assumed `do_classifier_free_guidance = guidance_scale > 1.0`
+ # implement this conditional `do_classifier_free_guidance = guidance_scale > 1.0`
+ batch_size = prompt_ids.shape[0]
+
+ max_length = prompt_ids.shape[-1]
+
+ if neg_prompt_ids is None:
+ uncond_input = self.tokenizer(
+ [""] * batch_size, padding="max_length", max_length=max_length, return_tensors="np"
+ ).input_ids
+ else:
+ uncond_input = neg_prompt_ids
+ negative_prompt_embeds = self.text_encoder(uncond_input, params=params["text_encoder"])[0]
+ context = jnp.concatenate([negative_prompt_embeds, prompt_embeds])
+
+ image = jnp.concatenate([image] * 2)
+
+ latents_shape = (
+ batch_size,
+ self.unet.config.in_channels,
+ height // self.vae_scale_factor,
+ width // self.vae_scale_factor,
+ )
+ if latents is None:
+ latents = jax.random.normal(prng_seed, shape=latents_shape, dtype=jnp.float32)
+ else:
+ if latents.shape != latents_shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
+
+ def loop_body(step, args):
+ latents, scheduler_state = args
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ latents_input = jnp.concatenate([latents] * 2)
+
+ t = jnp.array(scheduler_state.timesteps, dtype=jnp.int32)[step]
+ timestep = jnp.broadcast_to(t, latents_input.shape[0])
+
+ latents_input = self.scheduler.scale_model_input(scheduler_state, latents_input, t)
+
+ down_block_res_samples, mid_block_res_sample = self.controlnet.apply(
+ {"params": params["controlnet"]},
+ jnp.array(latents_input),
+ jnp.array(timestep, dtype=jnp.int32),
+ encoder_hidden_states=context,
+ controlnet_cond=image,
+ conditioning_scale=controlnet_conditioning_scale,
+ return_dict=False,
+ )
+
+ # predict the noise residual
+ noise_pred = self.unet.apply(
+ {"params": params["unet"]},
+ jnp.array(latents_input),
+ jnp.array(timestep, dtype=jnp.int32),
+ encoder_hidden_states=context,
+ down_block_additional_residuals=down_block_res_samples,
+ mid_block_additional_residual=mid_block_res_sample,
+ ).sample
+
+ # perform guidance
+ noise_pred_uncond, noise_prediction_text = jnp.split(noise_pred, 2, axis=0)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents, scheduler_state = self.scheduler.step(scheduler_state, noise_pred, t, latents).to_tuple()
+ return latents, scheduler_state
+
+ scheduler_state = self.scheduler.set_timesteps(
+ params["scheduler"], num_inference_steps=num_inference_steps, shape=latents_shape
+ )
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * params["scheduler"].init_noise_sigma
+
+ if DEBUG:
+ # run with python for loop
+ for i in range(num_inference_steps):
+ latents, scheduler_state = loop_body(i, (latents, scheduler_state))
+ else:
+ latents, _ = jax.lax.fori_loop(0, num_inference_steps, loop_body, (latents, scheduler_state))
+
+ # scale and decode the image latents with vae
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.apply({"params": params["vae"]}, latents, method=self.vae.decode).sample
+
+ image = (image / 2 + 0.5).clip(0, 1).transpose(0, 2, 3, 1)
+ return image
+
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt_ids: jnp.array,
+ image: jnp.array,
+ params: Union[Dict, FrozenDict],
+ prng_seed: jax.random.KeyArray,
+ num_inference_steps: int = 50,
+ guidance_scale: Union[float, jnp.array] = 7.5,
+ latents: jnp.array = None,
+ neg_prompt_ids: jnp.array = None,
+ controlnet_conditioning_scale: Union[float, jnp.array] = 1.0,
+ return_dict: bool = True,
+ jit: bool = False,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt_ids (`jnp.array`):
+ The prompt or prompts to guide the image generation.
+ image (`jnp.array`):
+ Array representing the ControlNet input condition. ControlNet use this input condition to generate
+ guidance to Unet.
+ params (`Dict` or `FrozenDict`): Dictionary containing the model parameters/weights
+ prng_seed (`jax.random.KeyArray` or `jax.Array`): Array containing random number generator key
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ latents (`jnp.array`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ controlnet_conditioning_scale (`float` or `jnp.array`, *optional*, defaults to 1.0):
+ The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
+ to the residual in the original unet.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] instead of
+ a plain tuple.
+ jit (`bool`, defaults to `False`):
+ Whether to run `pmap` versions of the generation and safety scoring functions. NOTE: This argument
+ exists because `__call__` is not yet end-to-end pmap-able. It will be removed in a future release.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a
+ `tuple. When returning a tuple, the first element is a list with the generated images, and the second
+ element is a list of `bool`s denoting whether the corresponding generated image likely represents
+ "not-safe-for-work" (nsfw) content, according to the `safety_checker`.
+ """
+
+ height, width = image.shape[-2:]
+
+ if isinstance(guidance_scale, float):
+ # Convert to a tensor so each device gets a copy. Follow the prompt_ids for
+ # shape information, as they may be sharded (when `jit` is `True`), or not.
+ guidance_scale = jnp.array([guidance_scale] * prompt_ids.shape[0])
+ if len(prompt_ids.shape) > 2:
+ # Assume sharded
+ guidance_scale = guidance_scale[:, None]
+
+ if isinstance(controlnet_conditioning_scale, float):
+ # Convert to a tensor so each device gets a copy. Follow the prompt_ids for
+ # shape information, as they may be sharded (when `jit` is `True`), or not.
+ controlnet_conditioning_scale = jnp.array([controlnet_conditioning_scale] * prompt_ids.shape[0])
+ if len(prompt_ids.shape) > 2:
+ # Assume sharded
+ controlnet_conditioning_scale = controlnet_conditioning_scale[:, None]
+
+ if jit:
+ images = _p_generate(
+ self,
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ controlnet_conditioning_scale,
+ )
+ else:
+ images = self._generate(
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ controlnet_conditioning_scale,
+ )
+
+ if self.safety_checker is not None:
+ safety_params = params["safety_checker"]
+ images_uint8_casted = (images * 255).round().astype("uint8")
+ num_devices, batch_size = images.shape[:2]
+
+ images_uint8_casted = np.asarray(images_uint8_casted).reshape(num_devices * batch_size, height, width, 3)
+ images_uint8_casted, has_nsfw_concept = self._run_safety_checker(images_uint8_casted, safety_params, jit)
+ images = np.asarray(images)
+
+ # block images
+ if any(has_nsfw_concept):
+ for i, is_nsfw in enumerate(has_nsfw_concept):
+ if is_nsfw:
+ images[i] = np.asarray(images_uint8_casted[i])
+
+ images = images.reshape(num_devices, batch_size, height, width, 3)
+ else:
+ images = np.asarray(images)
+ has_nsfw_concept = False
+
+ if not return_dict:
+ return (images, has_nsfw_concept)
+
+ return FlaxStableDiffusionPipelineOutput(images=images, nsfw_content_detected=has_nsfw_concept)
+
+
+# Static argnums are pipe, num_inference_steps. A change would trigger recompilation.
+# Non-static args are (sharded) input tensors mapped over their first dimension (hence, `0`).
+@partial(
+ jax.pmap,
+ in_axes=(None, 0, 0, 0, 0, None, 0, 0, 0, 0),
+ static_broadcasted_argnums=(0, 5),
+)
+def _p_generate(
+ pipe,
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ controlnet_conditioning_scale,
+):
+ return pipe._generate(
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ controlnet_conditioning_scale,
+ )
+
+
+@partial(jax.pmap, static_broadcasted_argnums=(0,))
+def _p_get_has_nsfw_concepts(pipe, features, params):
+ return pipe._get_has_nsfw_concepts(features, params)
+
+
+def unshard(x: jnp.ndarray):
+ # einops.rearrange(x, 'd b ... -> (d b) ...')
+ num_devices, batch_size = x.shape[:2]
+ rest = x.shape[2:]
+ return x.reshape(num_devices * batch_size, *rest)
+
+
+def preprocess(image, dtype):
+ image = image.convert("RGB")
+ w, h = image.size
+ w, h = (x - x % 64 for x in (w, h)) # resize to integer multiple of 64
+ image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
+ image = jnp.array(image).astype(dtype) / 255.0
+ image = image[None].transpose(0, 3, 1, 2)
+ return image
diff --git a/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py b/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py
index e3fe20e196d8..911a5018de18 100644
--- a/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py
+++ b/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py
@@ -8,10 +8,10 @@
from ...image_processor import VaeImageProcessor
from ...models import AutoencoderKL, UNet2DConditionModel
-from ...pipeline_utils import DiffusionPipeline
from ...pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from ...schedulers import KarrasDiffusionSchedulers
from ...utils import logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline
from . import SemanticStableDiffusionPipelineOutput
diff --git a/src/diffusers/pipelines/stable_diffusion/__init__.py b/src/diffusers/pipelines/stable_diffusion/__init__.py
index b89dde319cb3..f39ae67a9aff 100644
--- a/src/diffusers/pipelines/stable_diffusion/__init__.py
+++ b/src/diffusers/pipelines/stable_diffusion/__init__.py
@@ -45,7 +45,6 @@ class StableDiffusionPipelineOutput(BaseOutput):
from .pipeline_cycle_diffusion import CycleDiffusionPipeline
from .pipeline_stable_diffusion import StableDiffusionPipeline
from .pipeline_stable_diffusion_attend_and_excite import StableDiffusionAttendAndExcitePipeline
- from .pipeline_stable_diffusion_controlnet import StableDiffusionControlNetPipeline
from .pipeline_stable_diffusion_img2img import StableDiffusionImg2ImgPipeline
from .pipeline_stable_diffusion_inpaint import StableDiffusionInpaintPipeline
from .pipeline_stable_diffusion_inpaint_legacy import StableDiffusionInpaintPipelineLegacy
@@ -130,7 +129,6 @@ class FlaxStableDiffusionPipelineOutput(BaseOutput):
from ...schedulers.scheduling_pndm_flax import PNDMSchedulerState
from .pipeline_flax_stable_diffusion import FlaxStableDiffusionPipeline
- from .pipeline_flax_stable_diffusion_controlnet import FlaxStableDiffusionControlNetPipeline
from .pipeline_flax_stable_diffusion_img2img import FlaxStableDiffusionImg2ImgPipeline
from .pipeline_flax_stable_diffusion_inpaint import FlaxStableDiffusionInpaintPipeline
from .safety_checker_flax import FlaxStableDiffusionSafetyChecker
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_controlnet.py b/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_controlnet.py
index 7035242a0cda..bec2424ece4d 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_controlnet.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_controlnet.py
@@ -12,526 +12,17 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import warnings
-from functools import partial
-from typing import Dict, List, Optional, Union
+# NOTE: This file is deprecated and will be removed in a future version.
+# It only exists so that temporarely `from diffusers.pipelines import DiffusionPipeline` works
-import jax
-import jax.numpy as jnp
-import numpy as np
-from flax.core.frozen_dict import FrozenDict
-from flax.jax_utils import unreplicate
-from flax.training.common_utils import shard
-from PIL import Image
-from transformers import CLIPFeatureExtractor, CLIPTokenizer, FlaxCLIPTextModel
+from ...utils import deprecate
+from ..controlnet.pipeline_flax_controlnet import FlaxStableDiffusionControlNetPipeline # noqa: F401
-from ...models import FlaxAutoencoderKL, FlaxControlNetModel, FlaxUNet2DConditionModel
-from ...schedulers import (
- FlaxDDIMScheduler,
- FlaxDPMSolverMultistepScheduler,
- FlaxLMSDiscreteScheduler,
- FlaxPNDMScheduler,
-)
-from ...utils import PIL_INTERPOLATION, logging, replace_example_docstring
-from ..pipeline_flax_utils import FlaxDiffusionPipeline
-from . import FlaxStableDiffusionPipelineOutput
-from .safety_checker_flax import FlaxStableDiffusionSafetyChecker
-
-
-logger = logging.get_logger(__name__) # pylint: disable=invalid-name
-
-# Set to True to use python for loop instead of jax.fori_loop for easier debugging
-DEBUG = False
-
-EXAMPLE_DOC_STRING = """
- Examples:
- ```py
- >>> import jax
- >>> import numpy as np
- >>> import jax.numpy as jnp
- >>> from flax.jax_utils import replicate
- >>> from flax.training.common_utils import shard
- >>> from diffusers.utils import load_image
- >>> from PIL import Image
- >>> from diffusers import FlaxStableDiffusionControlNetPipeline, FlaxControlNetModel
-
-
- >>> def image_grid(imgs, rows, cols):
- ... w, h = imgs[0].size
- ... grid = Image.new("RGB", size=(cols * w, rows * h))
- ... for i, img in enumerate(imgs):
- ... grid.paste(img, box=(i % cols * w, i // cols * h))
- ... return grid
-
-
- >>> def create_key(seed=0):
- ... return jax.random.PRNGKey(seed)
-
-
- >>> rng = create_key(0)
-
- >>> # get canny image
- >>> canny_image = load_image(
- ... "https://huggingface.co/datasets/YiYiXu/test-doc-assets/resolve/main/blog_post_cell_10_output_0.jpeg"
- ... )
-
- >>> prompts = "best quality, extremely detailed"
- >>> negative_prompts = "monochrome, lowres, bad anatomy, worst quality, low quality"
-
- >>> # load control net and stable diffusion v1-5
- >>> controlnet, controlnet_params = FlaxControlNetModel.from_pretrained(
- ... "lllyasviel/sd-controlnet-canny", from_pt=True, dtype=jnp.float32
- ... )
- >>> pipe, params = FlaxStableDiffusionControlNetPipeline.from_pretrained(
- ... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, revision="flax", dtype=jnp.float32
- ... )
- >>> params["controlnet"] = controlnet_params
-
- >>> num_samples = jax.device_count()
- >>> rng = jax.random.split(rng, jax.device_count())
-
- >>> prompt_ids = pipe.prepare_text_inputs([prompts] * num_samples)
- >>> negative_prompt_ids = pipe.prepare_text_inputs([negative_prompts] * num_samples)
- >>> processed_image = pipe.prepare_image_inputs([canny_image] * num_samples)
-
- >>> p_params = replicate(params)
- >>> prompt_ids = shard(prompt_ids)
- >>> negative_prompt_ids = shard(negative_prompt_ids)
- >>> processed_image = shard(processed_image)
-
- >>> output = pipe(
- ... prompt_ids=prompt_ids,
- ... image=processed_image,
- ... params=p_params,
- ... prng_seed=rng,
- ... num_inference_steps=50,
- ... neg_prompt_ids=negative_prompt_ids,
- ... jit=True,
- ... ).images
-
- >>> output_images = pipe.numpy_to_pil(np.asarray(output.reshape((num_samples,) + output.shape[-3:])))
- >>> output_images = image_grid(output_images, num_samples // 4, 4)
- >>> output_images.save("generated_image.png")
- ```
-"""
-
-
-class FlaxStableDiffusionControlNetPipeline(FlaxDiffusionPipeline):
- r"""
- Pipeline for text-to-image generation using Stable Diffusion with ControlNet Guidance.
-
- This model inherits from [`FlaxDiffusionPipeline`]. Check the superclass documentation for the generic methods the
- library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
-
- Args:
- vae ([`FlaxAutoencoderKL`]):
- Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
- text_encoder ([`FlaxCLIPTextModel`]):
- Frozen text-encoder. Stable Diffusion uses the text portion of
- [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.FlaxCLIPTextModel),
- specifically the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
- tokenizer (`CLIPTokenizer`):
- Tokenizer of class
- [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
- unet ([`FlaxUNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
- controlnet ([`FlaxControlNetModel`]:
- Provides additional conditioning to the unet during the denoising process.
- scheduler ([`SchedulerMixin`]):
- A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
- [`FlaxDDIMScheduler`], [`FlaxLMSDiscreteScheduler`], [`FlaxPNDMScheduler`], or
- [`FlaxDPMSolverMultistepScheduler`].
- safety_checker ([`FlaxStableDiffusionSafetyChecker`]):
- Classification module that estimates whether generated images could be considered offensive or harmful.
- Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
- feature_extractor ([`CLIPFeatureExtractor`]):
- Model that extracts features from generated images to be used as inputs for the `safety_checker`.
- """
-
- def __init__(
- self,
- vae: FlaxAutoencoderKL,
- text_encoder: FlaxCLIPTextModel,
- tokenizer: CLIPTokenizer,
- unet: FlaxUNet2DConditionModel,
- controlnet: FlaxControlNetModel,
- scheduler: Union[
- FlaxDDIMScheduler, FlaxPNDMScheduler, FlaxLMSDiscreteScheduler, FlaxDPMSolverMultistepScheduler
- ],
- safety_checker: FlaxStableDiffusionSafetyChecker,
- feature_extractor: CLIPFeatureExtractor,
- dtype: jnp.dtype = jnp.float32,
- ):
- super().__init__()
- self.dtype = dtype
-
- if safety_checker is None:
- logger.warn(
- f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
- " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
- " results in services or applications open to the public. Both the diffusers team and Hugging Face"
- " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
- " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
- " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
- )
-
- self.register_modules(
- vae=vae,
- text_encoder=text_encoder,
- tokenizer=tokenizer,
- unet=unet,
- controlnet=controlnet,
- scheduler=scheduler,
- safety_checker=safety_checker,
- feature_extractor=feature_extractor,
- )
- self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
-
- def prepare_text_inputs(self, prompt: Union[str, List[str]]):
- if not isinstance(prompt, (str, list)):
- raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
-
- text_input = self.tokenizer(
- prompt,
- padding="max_length",
- max_length=self.tokenizer.model_max_length,
- truncation=True,
- return_tensors="np",
- )
-
- return text_input.input_ids
-
- def prepare_image_inputs(self, image: Union[Image.Image, List[Image.Image]]):
- if not isinstance(image, (Image.Image, list)):
- raise ValueError(f"image has to be of type `PIL.Image.Image` or list but is {type(image)}")
-
- if isinstance(image, Image.Image):
- image = [image]
-
- processed_images = jnp.concatenate([preprocess(img, jnp.float32) for img in image])
-
- return processed_images
-
- def _get_has_nsfw_concepts(self, features, params):
- has_nsfw_concepts = self.safety_checker(features, params)
- return has_nsfw_concepts
-
- def _run_safety_checker(self, images, safety_model_params, jit=False):
- # safety_model_params should already be replicated when jit is True
- pil_images = [Image.fromarray(image) for image in images]
- features = self.feature_extractor(pil_images, return_tensors="np").pixel_values
-
- if jit:
- features = shard(features)
- has_nsfw_concepts = _p_get_has_nsfw_concepts(self, features, safety_model_params)
- has_nsfw_concepts = unshard(has_nsfw_concepts)
- safety_model_params = unreplicate(safety_model_params)
- else:
- has_nsfw_concepts = self._get_has_nsfw_concepts(features, safety_model_params)
-
- images_was_copied = False
- for idx, has_nsfw_concept in enumerate(has_nsfw_concepts):
- if has_nsfw_concept:
- if not images_was_copied:
- images_was_copied = True
- images = images.copy()
-
- images[idx] = np.zeros(images[idx].shape, dtype=np.uint8) # black image
-
- if any(has_nsfw_concepts):
- warnings.warn(
- "Potential NSFW content was detected in one or more images. A black image will be returned"
- " instead. Try again with a different prompt and/or seed."
- )
-
- return images, has_nsfw_concepts
- def _generate(
- self,
- prompt_ids: jnp.array,
- image: jnp.array,
- params: Union[Dict, FrozenDict],
- prng_seed: jax.random.KeyArray,
- num_inference_steps: int,
- guidance_scale: float,
- latents: Optional[jnp.array] = None,
- neg_prompt_ids: Optional[jnp.array] = None,
- controlnet_conditioning_scale: float = 1.0,
- ):
- height, width = image.shape[-2:]
- if height % 64 != 0 or width % 64 != 0:
- raise ValueError(f"`height` and `width` have to be divisible by 64 but are {height} and {width}.")
-
- # get prompt text embeddings
- prompt_embeds = self.text_encoder(prompt_ids, params=params["text_encoder"])[0]
-
- # TODO: currently it is assumed `do_classifier_free_guidance = guidance_scale > 1.0`
- # implement this conditional `do_classifier_free_guidance = guidance_scale > 1.0`
- batch_size = prompt_ids.shape[0]
-
- max_length = prompt_ids.shape[-1]
-
- if neg_prompt_ids is None:
- uncond_input = self.tokenizer(
- [""] * batch_size, padding="max_length", max_length=max_length, return_tensors="np"
- ).input_ids
- else:
- uncond_input = neg_prompt_ids
- negative_prompt_embeds = self.text_encoder(uncond_input, params=params["text_encoder"])[0]
- context = jnp.concatenate([negative_prompt_embeds, prompt_embeds])
-
- image = jnp.concatenate([image] * 2)
-
- latents_shape = (
- batch_size,
- self.unet.config.in_channels,
- height // self.vae_scale_factor,
- width // self.vae_scale_factor,
- )
- if latents is None:
- latents = jax.random.normal(prng_seed, shape=latents_shape, dtype=jnp.float32)
- else:
- if latents.shape != latents_shape:
- raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
-
- def loop_body(step, args):
- latents, scheduler_state = args
- # For classifier free guidance, we need to do two forward passes.
- # Here we concatenate the unconditional and text embeddings into a single batch
- # to avoid doing two forward passes
- latents_input = jnp.concatenate([latents] * 2)
-
- t = jnp.array(scheduler_state.timesteps, dtype=jnp.int32)[step]
- timestep = jnp.broadcast_to(t, latents_input.shape[0])
-
- latents_input = self.scheduler.scale_model_input(scheduler_state, latents_input, t)
-
- down_block_res_samples, mid_block_res_sample = self.controlnet.apply(
- {"params": params["controlnet"]},
- jnp.array(latents_input),
- jnp.array(timestep, dtype=jnp.int32),
- encoder_hidden_states=context,
- controlnet_cond=image,
- conditioning_scale=controlnet_conditioning_scale,
- return_dict=False,
- )
-
- # predict the noise residual
- noise_pred = self.unet.apply(
- {"params": params["unet"]},
- jnp.array(latents_input),
- jnp.array(timestep, dtype=jnp.int32),
- encoder_hidden_states=context,
- down_block_additional_residuals=down_block_res_samples,
- mid_block_additional_residual=mid_block_res_sample,
- ).sample
-
- # perform guidance
- noise_pred_uncond, noise_prediction_text = jnp.split(noise_pred, 2, axis=0)
- noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)
-
- # compute the previous noisy sample x_t -> x_t-1
- latents, scheduler_state = self.scheduler.step(scheduler_state, noise_pred, t, latents).to_tuple()
- return latents, scheduler_state
-
- scheduler_state = self.scheduler.set_timesteps(
- params["scheduler"], num_inference_steps=num_inference_steps, shape=latents_shape
- )
-
- # scale the initial noise by the standard deviation required by the scheduler
- latents = latents * params["scheduler"].init_noise_sigma
-
- if DEBUG:
- # run with python for loop
- for i in range(num_inference_steps):
- latents, scheduler_state = loop_body(i, (latents, scheduler_state))
- else:
- latents, _ = jax.lax.fori_loop(0, num_inference_steps, loop_body, (latents, scheduler_state))
-
- # scale and decode the image latents with vae
- latents = 1 / self.vae.config.scaling_factor * latents
- image = self.vae.apply({"params": params["vae"]}, latents, method=self.vae.decode).sample
-
- image = (image / 2 + 0.5).clip(0, 1).transpose(0, 2, 3, 1)
- return image
-
- @replace_example_docstring(EXAMPLE_DOC_STRING)
- def __call__(
- self,
- prompt_ids: jnp.array,
- image: jnp.array,
- params: Union[Dict, FrozenDict],
- prng_seed: jax.random.KeyArray,
- num_inference_steps: int = 50,
- guidance_scale: Union[float, jnp.array] = 7.5,
- latents: jnp.array = None,
- neg_prompt_ids: jnp.array = None,
- controlnet_conditioning_scale: Union[float, jnp.array] = 1.0,
- return_dict: bool = True,
- jit: bool = False,
- ):
- r"""
- Function invoked when calling the pipeline for generation.
-
- Args:
- prompt_ids (`jnp.array`):
- The prompt or prompts to guide the image generation.
- image (`jnp.array`):
- Array representing the ControlNet input condition. ControlNet use this input condition to generate
- guidance to Unet.
- params (`Dict` or `FrozenDict`): Dictionary containing the model parameters/weights
- prng_seed (`jax.random.KeyArray` or `jax.Array`): Array containing random number generator key
- num_inference_steps (`int`, *optional*, defaults to 50):
- The number of denoising steps. More denoising steps usually lead to a higher quality image at the
- expense of slower inference.
- guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
- latents (`jnp.array`, *optional*):
- Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
- generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
- tensor will ge generated by sampling using the supplied random `generator`.
- controlnet_conditioning_scale (`float` or `jnp.array`, *optional*, defaults to 1.0):
- The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
- to the residual in the original unet.
- return_dict (`bool`, *optional*, defaults to `True`):
- Whether or not to return a [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] instead of
- a plain tuple.
- jit (`bool`, defaults to `False`):
- Whether to run `pmap` versions of the generation and safety scoring functions. NOTE: This argument
- exists because `__call__` is not yet end-to-end pmap-able. It will be removed in a future release.
-
- Examples:
-
- Returns:
- [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] or `tuple`:
- [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a
- `tuple. When returning a tuple, the first element is a list with the generated images, and the second
- element is a list of `bool`s denoting whether the corresponding generated image likely represents
- "not-safe-for-work" (nsfw) content, according to the `safety_checker`.
- """
-
- height, width = image.shape[-2:]
-
- if isinstance(guidance_scale, float):
- # Convert to a tensor so each device gets a copy. Follow the prompt_ids for
- # shape information, as they may be sharded (when `jit` is `True`), or not.
- guidance_scale = jnp.array([guidance_scale] * prompt_ids.shape[0])
- if len(prompt_ids.shape) > 2:
- # Assume sharded
- guidance_scale = guidance_scale[:, None]
-
- if isinstance(controlnet_conditioning_scale, float):
- # Convert to a tensor so each device gets a copy. Follow the prompt_ids for
- # shape information, as they may be sharded (when `jit` is `True`), or not.
- controlnet_conditioning_scale = jnp.array([controlnet_conditioning_scale] * prompt_ids.shape[0])
- if len(prompt_ids.shape) > 2:
- # Assume sharded
- controlnet_conditioning_scale = controlnet_conditioning_scale[:, None]
-
- if jit:
- images = _p_generate(
- self,
- prompt_ids,
- image,
- params,
- prng_seed,
- num_inference_steps,
- guidance_scale,
- latents,
- neg_prompt_ids,
- controlnet_conditioning_scale,
- )
- else:
- images = self._generate(
- prompt_ids,
- image,
- params,
- prng_seed,
- num_inference_steps,
- guidance_scale,
- latents,
- neg_prompt_ids,
- controlnet_conditioning_scale,
- )
-
- if self.safety_checker is not None:
- safety_params = params["safety_checker"]
- images_uint8_casted = (images * 255).round().astype("uint8")
- num_devices, batch_size = images.shape[:2]
-
- images_uint8_casted = np.asarray(images_uint8_casted).reshape(num_devices * batch_size, height, width, 3)
- images_uint8_casted, has_nsfw_concept = self._run_safety_checker(images_uint8_casted, safety_params, jit)
- images = np.asarray(images)
-
- # block images
- if any(has_nsfw_concept):
- for i, is_nsfw in enumerate(has_nsfw_concept):
- if is_nsfw:
- images[i] = np.asarray(images_uint8_casted[i])
-
- images = images.reshape(num_devices, batch_size, height, width, 3)
- else:
- images = np.asarray(images)
- has_nsfw_concept = False
-
- if not return_dict:
- return (images, has_nsfw_concept)
-
- return FlaxStableDiffusionPipelineOutput(images=images, nsfw_content_detected=has_nsfw_concept)
-
-
-# Static argnums are pipe, num_inference_steps. A change would trigger recompilation.
-# Non-static args are (sharded) input tensors mapped over their first dimension (hence, `0`).
-@partial(
- jax.pmap,
- in_axes=(None, 0, 0, 0, 0, None, 0, 0, 0, 0),
- static_broadcasted_argnums=(0, 5),
+deprecate(
+ "stable diffusion controlnet",
+ "0.22.0",
+ "Importing `FlaxStableDiffusionControlNetPipeline` from diffusers.pipelines.stable_diffusion.flax_pipeline_stable_diffusion_controlnet is deprecated. Please import `from diffusers import FlaxStableDiffusionControlNetPipeline` instead.",
+ standard_warn=False,
+ stacklevel=3,
)
-def _p_generate(
- pipe,
- prompt_ids,
- image,
- params,
- prng_seed,
- num_inference_steps,
- guidance_scale,
- latents,
- neg_prompt_ids,
- controlnet_conditioning_scale,
-):
- return pipe._generate(
- prompt_ids,
- image,
- params,
- prng_seed,
- num_inference_steps,
- guidance_scale,
- latents,
- neg_prompt_ids,
- controlnet_conditioning_scale,
- )
-
-
-@partial(jax.pmap, static_broadcasted_argnums=(0,))
-def _p_get_has_nsfw_concepts(pipe, features, params):
- return pipe._get_has_nsfw_concepts(features, params)
-
-
-def unshard(x: jnp.ndarray):
- # einops.rearrange(x, 'd b ... -> (d b) ...')
- num_devices, batch_size = x.shape[:2]
- rest = x.shape[2:]
- return x.reshape(num_devices * batch_size, *rest)
-
-
-def preprocess(image, dtype):
- image = image.convert("RGB")
- w, h = image.size
- w, h = (x - x % 64 for x in (w, h)) # resize to integer multiple of 64
- image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
- image = jnp.array(image).astype(dtype) / 255.0
- image = image[None].transpose(0, 3, 1, 2)
- return image
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py
index 1cef221ea6e1..c7555e2ebad4 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py
@@ -12,1093 +12,17 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-
-import inspect
-import os
-import warnings
-from typing import Any, Callable, Dict, List, Optional, Tuple, Union
-
-import numpy as np
-import PIL.Image
-import torch
-import torch.nn.functional as F
-from torch import nn
-from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
-
-from ...image_processor import VaeImageProcessor
-from ...loaders import TextualInversionLoaderMixin
-from ...models import AutoencoderKL, ControlNetModel, UNet2DConditionModel
-from ...models.controlnet import ControlNetOutput
-from ...models.modeling_utils import ModelMixin
-from ...schedulers import KarrasDiffusionSchedulers
-from ...utils import (
- PIL_INTERPOLATION,
- is_accelerate_available,
- is_accelerate_version,
- logging,
- randn_tensor,
- replace_example_docstring,
+# NOTE: This file is deprecated and will be removed in a future version.
+# It only exists so that temporarely `from diffusers.pipelines import DiffusionPipeline` works
+from ...utils import deprecate
+from ..controlnet.multicontrolnet import MultiControlNetModel # noqa: F401
+from ..controlnet.pipeline_controlnet import StableDiffusionControlNetPipeline # noqa: F401
+
+
+deprecate(
+ "stable diffusion controlnet",
+ "0.22.0",
+ "Importing `StableDiffusionControlNetPipeline` or `MultiControlNetModel` from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_controlnet is deprecated. Please import `from diffusers import StableDiffusionControlNetPipeline` instead.",
+ standard_warn=False,
+ stacklevel=3,
)
-from ..pipeline_utils import DiffusionPipeline
-from . import StableDiffusionPipelineOutput
-from .safety_checker import StableDiffusionSafetyChecker
-
-
-logger = logging.get_logger(__name__) # pylint: disable=invalid-name
-
-
-EXAMPLE_DOC_STRING = """
- Examples:
- ```py
- >>> # !pip install opencv-python transformers accelerate
- >>> from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
- >>> from diffusers.utils import load_image
- >>> import numpy as np
- >>> import torch
-
- >>> import cv2
- >>> from PIL import Image
-
- >>> # download an image
- >>> image = load_image(
- ... "https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
- ... )
- >>> image = np.array(image)
-
- >>> # get canny image
- >>> image = cv2.Canny(image, 100, 200)
- >>> image = image[:, :, None]
- >>> image = np.concatenate([image, image, image], axis=2)
- >>> canny_image = Image.fromarray(image)
-
- >>> # load control net and stable diffusion v1-5
- >>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
- >>> pipe = StableDiffusionControlNetPipeline.from_pretrained(
- ... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
- ... )
-
- >>> # speed up diffusion process with faster scheduler and memory optimization
- >>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
- >>> # remove following line if xformers is not installed
- >>> pipe.enable_xformers_memory_efficient_attention()
-
- >>> pipe.enable_model_cpu_offload()
-
- >>> # generate image
- >>> generator = torch.manual_seed(0)
- >>> image = pipe(
- ... "futuristic-looking woman", num_inference_steps=20, generator=generator, image=canny_image
- ... ).images[0]
- ```
-"""
-
-
-class MultiControlNetModel(ModelMixin):
- r"""
- Multiple `ControlNetModel` wrapper class for Multi-ControlNet
-
- This module is a wrapper for multiple instances of the `ControlNetModel`. The `forward()` API is designed to be
- compatible with `ControlNetModel`.
-
- Args:
- controlnets (`List[ControlNetModel]`):
- Provides additional conditioning to the unet during the denoising process. You must set multiple
- `ControlNetModel` as a list.
- """
-
- def __init__(self, controlnets: Union[List[ControlNetModel], Tuple[ControlNetModel]]):
- super().__init__()
- self.nets = nn.ModuleList(controlnets)
-
- def forward(
- self,
- sample: torch.FloatTensor,
- timestep: Union[torch.Tensor, float, int],
- encoder_hidden_states: torch.Tensor,
- controlnet_cond: List[torch.tensor],
- conditioning_scale: List[float],
- class_labels: Optional[torch.Tensor] = None,
- timestep_cond: Optional[torch.Tensor] = None,
- attention_mask: Optional[torch.Tensor] = None,
- cross_attention_kwargs: Optional[Dict[str, Any]] = None,
- guess_mode: bool = False,
- return_dict: bool = True,
- ) -> Union[ControlNetOutput, Tuple]:
- for i, (image, scale, controlnet) in enumerate(zip(controlnet_cond, conditioning_scale, self.nets)):
- down_samples, mid_sample = controlnet(
- sample,
- timestep,
- encoder_hidden_states,
- image,
- scale,
- class_labels,
- timestep_cond,
- attention_mask,
- cross_attention_kwargs,
- guess_mode,
- return_dict,
- )
-
- # merge samples
- if i == 0:
- down_block_res_samples, mid_block_res_sample = down_samples, mid_sample
- else:
- down_block_res_samples = [
- samples_prev + samples_curr
- for samples_prev, samples_curr in zip(down_block_res_samples, down_samples)
- ]
- mid_block_res_sample += mid_sample
-
- return down_block_res_samples, mid_block_res_sample
-
-
-class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
- r"""
- Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
-
- This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
- library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
-
- In addition the pipeline inherits the following loading methods:
- - *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
-
- Args:
- vae ([`AutoencoderKL`]):
- Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
- text_encoder ([`CLIPTextModel`]):
- Frozen text-encoder. Stable Diffusion uses the text portion of
- [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
- the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
- tokenizer (`CLIPTokenizer`):
- Tokenizer of class
- [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
- unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
- controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
- Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets
- as a list, the outputs from each ControlNet are added together to create one combined additional
- conditioning.
- scheduler ([`SchedulerMixin`]):
- A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
- [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
- safety_checker ([`StableDiffusionSafetyChecker`]):
- Classification module that estimates whether generated images could be considered offensive or harmful.
- Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
- feature_extractor ([`CLIPImageProcessor`]):
- Model that extracts features from generated images to be used as inputs for the `safety_checker`.
- """
- _optional_components = ["safety_checker", "feature_extractor"]
-
- def __init__(
- self,
- vae: AutoencoderKL,
- text_encoder: CLIPTextModel,
- tokenizer: CLIPTokenizer,
- unet: UNet2DConditionModel,
- controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
- scheduler: KarrasDiffusionSchedulers,
- safety_checker: StableDiffusionSafetyChecker,
- feature_extractor: CLIPImageProcessor,
- requires_safety_checker: bool = True,
- ):
- super().__init__()
-
- if safety_checker is None and requires_safety_checker:
- logger.warning(
- f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
- " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
- " results in services or applications open to the public. Both the diffusers team and Hugging Face"
- " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
- " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
- " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
- )
-
- if safety_checker is not None and feature_extractor is None:
- raise ValueError(
- "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
- " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
- )
-
- if isinstance(controlnet, (list, tuple)):
- controlnet = MultiControlNetModel(controlnet)
-
- self.register_modules(
- vae=vae,
- text_encoder=text_encoder,
- tokenizer=tokenizer,
- unet=unet,
- controlnet=controlnet,
- scheduler=scheduler,
- safety_checker=safety_checker,
- feature_extractor=feature_extractor,
- )
- self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
- self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
- self.register_to_config(requires_safety_checker=requires_safety_checker)
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
- def enable_vae_slicing(self):
- r"""
- Enable sliced VAE decoding.
-
- When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
- steps. This is useful to save some memory and allow larger batch sizes.
- """
- self.vae.enable_slicing()
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
- def disable_vae_slicing(self):
- r"""
- Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
- computing decoding in one step.
- """
- self.vae.disable_slicing()
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
- def enable_vae_tiling(self):
- r"""
- Enable tiled VAE decoding.
-
- When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
- several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
- """
- self.vae.enable_tiling()
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
- def disable_vae_tiling(self):
- r"""
- Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
- computing decoding in one step.
- """
- self.vae.disable_tiling()
-
- def enable_sequential_cpu_offload(self, gpu_id=0):
- r"""
- Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
- text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
- `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
- Note that offloading happens on a submodule basis. Memory savings are higher than with
- `enable_model_cpu_offload`, but performance is lower.
- """
- if is_accelerate_available():
- from accelerate import cpu_offload
- else:
- raise ImportError("Please install accelerate via `pip install accelerate`")
-
- device = torch.device(f"cuda:{gpu_id}")
-
- for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.controlnet]:
- cpu_offload(cpu_offloaded_model, device)
-
- if self.safety_checker is not None:
- cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
-
- def enable_model_cpu_offload(self, gpu_id=0):
- r"""
- Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
- to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
- method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
- `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
- """
- if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
- from accelerate import cpu_offload_with_hook
- else:
- raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
-
- device = torch.device(f"cuda:{gpu_id}")
-
- hook = None
- for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
- _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
-
- if self.safety_checker is not None:
- # the safety checker can offload the vae again
- _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
-
- # control net hook has be manually offloaded as it alternates with unet
- cpu_offload_with_hook(self.controlnet, device)
-
- # We'll offload the last model manually.
- self.final_offload_hook = hook
-
- @property
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
- def _execution_device(self):
- r"""
- Returns the device on which the pipeline's models will be executed. After calling
- `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
- hooks.
- """
- if not hasattr(self.unet, "_hf_hook"):
- return self.device
- for module in self.unet.modules():
- if (
- hasattr(module, "_hf_hook")
- and hasattr(module._hf_hook, "execution_device")
- and module._hf_hook.execution_device is not None
- ):
- return torch.device(module._hf_hook.execution_device)
- return self.device
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
- def _encode_prompt(
- self,
- prompt,
- device,
- num_images_per_prompt,
- do_classifier_free_guidance,
- negative_prompt=None,
- prompt_embeds: Optional[torch.FloatTensor] = None,
- negative_prompt_embeds: Optional[torch.FloatTensor] = None,
- ):
- r"""
- Encodes the prompt into text encoder hidden states.
-
- Args:
- prompt (`str` or `List[str]`, *optional*):
- prompt to be encoded
- device: (`torch.device`):
- torch device
- num_images_per_prompt (`int`):
- number of images that should be generated per prompt
- do_classifier_free_guidance (`bool`):
- whether to use classifier free guidance or not
- negative_prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts not to guide the image generation. If not defined, one has to pass
- `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
- less than `1`).
- prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
- provided, text embeddings will be generated from `prompt` input argument.
- negative_prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
- weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
- argument.
- """
- if prompt is not None and isinstance(prompt, str):
- batch_size = 1
- elif prompt is not None and isinstance(prompt, list):
- batch_size = len(prompt)
- else:
- batch_size = prompt_embeds.shape[0]
-
- if prompt_embeds is None:
- # textual inversion: procecss multi-vector tokens if necessary
- if isinstance(self, TextualInversionLoaderMixin):
- prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
-
- text_inputs = self.tokenizer(
- prompt,
- padding="max_length",
- max_length=self.tokenizer.model_max_length,
- truncation=True,
- return_tensors="pt",
- )
- text_input_ids = text_inputs.input_ids
- untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
-
- if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
- text_input_ids, untruncated_ids
- ):
- removed_text = self.tokenizer.batch_decode(
- untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
- )
- logger.warning(
- "The following part of your input was truncated because CLIP can only handle sequences up to"
- f" {self.tokenizer.model_max_length} tokens: {removed_text}"
- )
-
- if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
- attention_mask = text_inputs.attention_mask.to(device)
- else:
- attention_mask = None
-
- prompt_embeds = self.text_encoder(
- text_input_ids.to(device),
- attention_mask=attention_mask,
- )
- prompt_embeds = prompt_embeds[0]
-
- prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
-
- bs_embed, seq_len, _ = prompt_embeds.shape
- # duplicate text embeddings for each generation per prompt, using mps friendly method
- prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
- prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
-
- # get unconditional embeddings for classifier free guidance
- if do_classifier_free_guidance and negative_prompt_embeds is None:
- uncond_tokens: List[str]
- if negative_prompt is None:
- uncond_tokens = [""] * batch_size
- elif prompt is not None and type(prompt) is not type(negative_prompt):
- raise TypeError(
- f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
- f" {type(prompt)}."
- )
- elif isinstance(negative_prompt, str):
- uncond_tokens = [negative_prompt]
- elif batch_size != len(negative_prompt):
- raise ValueError(
- f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
- f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
- " the batch size of `prompt`."
- )
- else:
- uncond_tokens = negative_prompt
-
- # textual inversion: procecss multi-vector tokens if necessary
- if isinstance(self, TextualInversionLoaderMixin):
- uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
-
- max_length = prompt_embeds.shape[1]
- uncond_input = self.tokenizer(
- uncond_tokens,
- padding="max_length",
- max_length=max_length,
- truncation=True,
- return_tensors="pt",
- )
-
- if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
- attention_mask = uncond_input.attention_mask.to(device)
- else:
- attention_mask = None
-
- negative_prompt_embeds = self.text_encoder(
- uncond_input.input_ids.to(device),
- attention_mask=attention_mask,
- )
- negative_prompt_embeds = negative_prompt_embeds[0]
-
- if do_classifier_free_guidance:
- # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
- seq_len = negative_prompt_embeds.shape[1]
-
- negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
-
- negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
- negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
-
- # For classifier free guidance, we need to do two forward passes.
- # Here we concatenate the unconditional and text embeddings into a single batch
- # to avoid doing two forward passes
- prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
-
- return prompt_embeds
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
- def run_safety_checker(self, image, device, dtype):
- if self.safety_checker is None:
- has_nsfw_concept = None
- else:
- if torch.is_tensor(image):
- feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
- else:
- feature_extractor_input = self.image_processor.numpy_to_pil(image)
- safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
- image, has_nsfw_concept = self.safety_checker(
- images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
- )
- return image, has_nsfw_concept
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
- def decode_latents(self, latents):
- warnings.warn(
- "The decode_latents method is deprecated and will be removed in a future version. Please"
- " use VaeImageProcessor instead",
- FutureWarning,
- )
- latents = 1 / self.vae.config.scaling_factor * latents
- image = self.vae.decode(latents, return_dict=False)[0]
- image = (image / 2 + 0.5).clamp(0, 1)
- # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
- image = image.cpu().permute(0, 2, 3, 1).float().numpy()
- return image
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
- def prepare_extra_step_kwargs(self, generator, eta):
- # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
- # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
- # and should be between [0, 1]
-
- accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
- extra_step_kwargs = {}
- if accepts_eta:
- extra_step_kwargs["eta"] = eta
-
- # check if the scheduler accepts generator
- accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
- if accepts_generator:
- extra_step_kwargs["generator"] = generator
- return extra_step_kwargs
-
- def check_inputs(
- self,
- prompt,
- image,
- height,
- width,
- callback_steps,
- negative_prompt=None,
- prompt_embeds=None,
- negative_prompt_embeds=None,
- controlnet_conditioning_scale=1.0,
- ):
- if height % 8 != 0 or width % 8 != 0:
- raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
-
- if (callback_steps is None) or (
- callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
- ):
- raise ValueError(
- f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
- f" {type(callback_steps)}."
- )
-
- if prompt is not None and prompt_embeds is not None:
- raise ValueError(
- f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
- " only forward one of the two."
- )
- elif prompt is None and prompt_embeds is None:
- raise ValueError(
- "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
- )
- elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
- raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
-
- if negative_prompt is not None and negative_prompt_embeds is not None:
- raise ValueError(
- f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
- f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
- )
-
- if prompt_embeds is not None and negative_prompt_embeds is not None:
- if prompt_embeds.shape != negative_prompt_embeds.shape:
- raise ValueError(
- "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
- f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
- f" {negative_prompt_embeds.shape}."
- )
-
- # `prompt` needs more sophisticated handling when there are multiple
- # conditionings.
- if isinstance(self.controlnet, MultiControlNetModel):
- if isinstance(prompt, list):
- logger.warning(
- f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
- " prompts. The conditionings will be fixed across the prompts."
- )
-
- # Check `image`
- is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
- self.controlnet, torch._dynamo.eval_frame.OptimizedModule
- )
- if (
- isinstance(self.controlnet, ControlNetModel)
- or is_compiled
- and isinstance(self.controlnet._orig_mod, ControlNetModel)
- ):
- self.check_image(image, prompt, prompt_embeds)
- elif (
- isinstance(self.controlnet, MultiControlNetModel)
- or is_compiled
- and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
- ):
- if not isinstance(image, list):
- raise TypeError("For multiple controlnets: `image` must be type `list`")
-
- # When `image` is a nested list:
- # (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
- elif any(isinstance(i, list) for i in image):
- raise ValueError("A single batch of multiple conditionings are supported at the moment.")
- elif len(image) != len(self.controlnet.nets):
- raise ValueError(
- "For multiple controlnets: `image` must have the same length as the number of controlnets."
- )
-
- for image_ in image:
- self.check_image(image_, prompt, prompt_embeds)
- else:
- assert False
-
- # Check `controlnet_conditioning_scale`
- if (
- isinstance(self.controlnet, ControlNetModel)
- or is_compiled
- and isinstance(self.controlnet._orig_mod, ControlNetModel)
- ):
- if not isinstance(controlnet_conditioning_scale, float):
- raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
- elif (
- isinstance(self.controlnet, MultiControlNetModel)
- or is_compiled
- and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
- ):
- if isinstance(controlnet_conditioning_scale, list):
- if any(isinstance(i, list) for i in controlnet_conditioning_scale):
- raise ValueError("A single batch of multiple conditionings are supported at the moment.")
- elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
- self.controlnet.nets
- ):
- raise ValueError(
- "For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
- " the same length as the number of controlnets"
- )
- else:
- assert False
-
- def check_image(self, image, prompt, prompt_embeds):
- image_is_pil = isinstance(image, PIL.Image.Image)
- image_is_tensor = isinstance(image, torch.Tensor)
- image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
- image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
-
- if not image_is_pil and not image_is_tensor and not image_is_pil_list and not image_is_tensor_list:
- raise TypeError(
- "image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
- )
-
- if image_is_pil:
- image_batch_size = 1
- elif image_is_tensor:
- image_batch_size = image.shape[0]
- elif image_is_pil_list:
- image_batch_size = len(image)
- elif image_is_tensor_list:
- image_batch_size = len(image)
-
- if prompt is not None and isinstance(prompt, str):
- prompt_batch_size = 1
- elif prompt is not None and isinstance(prompt, list):
- prompt_batch_size = len(prompt)
- elif prompt_embeds is not None:
- prompt_batch_size = prompt_embeds.shape[0]
-
- if image_batch_size != 1 and image_batch_size != prompt_batch_size:
- raise ValueError(
- f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
- )
-
- def prepare_image(
- self,
- image,
- width,
- height,
- batch_size,
- num_images_per_prompt,
- device,
- dtype,
- do_classifier_free_guidance=False,
- guess_mode=False,
- ):
- if not isinstance(image, torch.Tensor):
- if isinstance(image, PIL.Image.Image):
- image = [image]
-
- if isinstance(image[0], PIL.Image.Image):
- images = []
-
- for image_ in image:
- image_ = image_.convert("RGB")
- image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
- image_ = np.array(image_)
- image_ = image_[None, :]
- images.append(image_)
-
- image = images
-
- image = np.concatenate(image, axis=0)
- image = np.array(image).astype(np.float32) / 255.0
- image = image.transpose(0, 3, 1, 2)
- image = torch.from_numpy(image)
- elif isinstance(image[0], torch.Tensor):
- image = torch.cat(image, dim=0)
-
- image_batch_size = image.shape[0]
-
- if image_batch_size == 1:
- repeat_by = batch_size
- else:
- # image batch size is the same as prompt batch size
- repeat_by = num_images_per_prompt
-
- image = image.repeat_interleave(repeat_by, dim=0)
-
- image = image.to(device=device, dtype=dtype)
-
- if do_classifier_free_guidance and not guess_mode:
- image = torch.cat([image] * 2)
-
- return image
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
- def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
- shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
- if isinstance(generator, list) and len(generator) != batch_size:
- raise ValueError(
- f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
- f" size of {batch_size}. Make sure the batch size matches the length of the generators."
- )
-
- if latents is None:
- latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
- else:
- latents = latents.to(device)
-
- # scale the initial noise by the standard deviation required by the scheduler
- latents = latents * self.scheduler.init_noise_sigma
- return latents
-
- def _default_height_width(self, height, width, image):
- # NOTE: It is possible that a list of images have different
- # dimensions for each image, so just checking the first image
- # is not _exactly_ correct, but it is simple.
- while isinstance(image, list):
- image = image[0]
-
- if height is None:
- if isinstance(image, PIL.Image.Image):
- height = image.height
- elif isinstance(image, torch.Tensor):
- height = image.shape[2]
-
- height = (height // 8) * 8 # round down to nearest multiple of 8
-
- if width is None:
- if isinstance(image, PIL.Image.Image):
- width = image.width
- elif isinstance(image, torch.Tensor):
- width = image.shape[3]
-
- width = (width // 8) * 8 # round down to nearest multiple of 8
-
- return height, width
-
- # override DiffusionPipeline
- def save_pretrained(
- self,
- save_directory: Union[str, os.PathLike],
- safe_serialization: bool = False,
- variant: Optional[str] = None,
- ):
- if isinstance(self.controlnet, ControlNetModel):
- super().save_pretrained(save_directory, safe_serialization, variant)
- else:
- raise NotImplementedError("Currently, the `save_pretrained()` is not implemented for Multi-ControlNet.")
-
- @torch.no_grad()
- @replace_example_docstring(EXAMPLE_DOC_STRING)
- def __call__(
- self,
- prompt: Union[str, List[str]] = None,
- image: Union[torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]] = None,
- height: Optional[int] = None,
- width: Optional[int] = None,
- num_inference_steps: int = 50,
- guidance_scale: float = 7.5,
- negative_prompt: Optional[Union[str, List[str]]] = None,
- num_images_per_prompt: Optional[int] = 1,
- eta: float = 0.0,
- generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
- latents: Optional[torch.FloatTensor] = None,
- prompt_embeds: Optional[torch.FloatTensor] = None,
- negative_prompt_embeds: Optional[torch.FloatTensor] = None,
- output_type: Optional[str] = "pil",
- return_dict: bool = True,
- callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
- callback_steps: int = 1,
- cross_attention_kwargs: Optional[Dict[str, Any]] = None,
- controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
- guess_mode: bool = False,
- ):
- r"""
- Function invoked when calling the pipeline for generation.
-
- Args:
- prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
- instead.
- image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`,
- `List[List[torch.FloatTensor]]`, or `List[List[PIL.Image.Image]]`):
- The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
- the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
- also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
- height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
- specified in init, images must be passed as a list such that each element of the list can be correctly
- batched for input to a single controlnet.
- height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
- The height in pixels of the generated image.
- width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
- The width in pixels of the generated image.
- num_inference_steps (`int`, *optional*, defaults to 50):
- The number of denoising steps. More denoising steps usually lead to a higher quality image at the
- expense of slower inference.
- guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
- negative_prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts not to guide the image generation. If not defined, one has to pass
- `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
- less than `1`).
- num_images_per_prompt (`int`, *optional*, defaults to 1):
- The number of images to generate per prompt.
- eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
- generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
- One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
- to make generation deterministic.
- latents (`torch.FloatTensor`, *optional*):
- Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
- generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
- tensor will ge generated by sampling using the supplied random `generator`.
- prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
- provided, text embeddings will be generated from `prompt` input argument.
- negative_prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
- weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
- argument.
- output_type (`str`, *optional*, defaults to `"pil"`):
- The output format of the generate image. Choose between
- [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
- return_dict (`bool`, *optional*, defaults to `True`):
- Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
- plain tuple.
- callback (`Callable`, *optional*):
- A function that will be called every `callback_steps` steps during inference. The function will be
- called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
- callback_steps (`int`, *optional*, defaults to 1):
- The frequency at which the `callback` function will be called. If not specified, the callback will be
- called at every step.
- cross_attention_kwargs (`dict`, *optional*):
- A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
- `self.processor` in
- [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
- controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
- The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
- to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
- corresponding scale as a list.
- guess_mode (`bool`, *optional*, defaults to `False`):
- In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
- you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
-
- Examples:
-
- Returns:
- [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
- [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
- When returning a tuple, the first element is a list with the generated images, and the second element is a
- list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
- (nsfw) content, according to the `safety_checker`.
- """
- # 0. Default height and width to unet
- height, width = self._default_height_width(height, width, image)
-
- # 1. Check inputs. Raise error if not correct
- self.check_inputs(
- prompt,
- image,
- height,
- width,
- callback_steps,
- negative_prompt,
- prompt_embeds,
- negative_prompt_embeds,
- controlnet_conditioning_scale,
- )
-
- # 2. Define call parameters
- if prompt is not None and isinstance(prompt, str):
- batch_size = 1
- elif prompt is not None and isinstance(prompt, list):
- batch_size = len(prompt)
- else:
- batch_size = prompt_embeds.shape[0]
-
- device = self._execution_device
- # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
- # corresponds to doing no classifier free guidance.
- do_classifier_free_guidance = guidance_scale > 1.0
-
- if isinstance(self.controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
- controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(self.controlnet.nets)
-
- global_pool_conditions = (
- self.controlnet.config.global_pool_conditions
- if isinstance(self.controlnet, ControlNetModel)
- else self.controlnet.nets[0].config.global_pool_conditions
- )
- guess_mode = guess_mode or global_pool_conditions
-
- # 3. Encode input prompt
- prompt_embeds = self._encode_prompt(
- prompt,
- device,
- num_images_per_prompt,
- do_classifier_free_guidance,
- negative_prompt,
- prompt_embeds=prompt_embeds,
- negative_prompt_embeds=negative_prompt_embeds,
- )
-
- # 4. Prepare image
- is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
- self.controlnet, torch._dynamo.eval_frame.OptimizedModule
- )
- if (
- isinstance(self.controlnet, ControlNetModel)
- or is_compiled
- and isinstance(self.controlnet._orig_mod, ControlNetModel)
- ):
- image = self.prepare_image(
- image=image,
- width=width,
- height=height,
- batch_size=batch_size * num_images_per_prompt,
- num_images_per_prompt=num_images_per_prompt,
- device=device,
- dtype=self.controlnet.dtype,
- do_classifier_free_guidance=do_classifier_free_guidance,
- guess_mode=guess_mode,
- )
- elif (
- isinstance(self.controlnet, MultiControlNetModel)
- or is_compiled
- and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
- ):
- images = []
-
- for image_ in image:
- image_ = self.prepare_image(
- image=image_,
- width=width,
- height=height,
- batch_size=batch_size * num_images_per_prompt,
- num_images_per_prompt=num_images_per_prompt,
- device=device,
- dtype=self.controlnet.dtype,
- do_classifier_free_guidance=do_classifier_free_guidance,
- guess_mode=guess_mode,
- )
-
- images.append(image_)
-
- image = images
- else:
- assert False
-
- # 5. Prepare timesteps
- self.scheduler.set_timesteps(num_inference_steps, device=device)
- timesteps = self.scheduler.timesteps
-
- # 6. Prepare latent variables
- num_channels_latents = self.unet.config.in_channels
- latents = self.prepare_latents(
- batch_size * num_images_per_prompt,
- num_channels_latents,
- height,
- width,
- prompt_embeds.dtype,
- device,
- generator,
- latents,
- )
-
- # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
- extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
-
- # 8. Denoising loop
- num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
- with self.progress_bar(total=num_inference_steps) as progress_bar:
- for i, t in enumerate(timesteps):
- # expand the latents if we are doing classifier free guidance
- latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
- latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
-
- # controlnet(s) inference
- if guess_mode and do_classifier_free_guidance:
- # Infer ControlNet only for the conditional batch.
- controlnet_latent_model_input = latents
- controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
- else:
- controlnet_latent_model_input = latent_model_input
- controlnet_prompt_embeds = prompt_embeds
-
- down_block_res_samples, mid_block_res_sample = self.controlnet(
- controlnet_latent_model_input,
- t,
- encoder_hidden_states=controlnet_prompt_embeds,
- controlnet_cond=image,
- conditioning_scale=controlnet_conditioning_scale,
- guess_mode=guess_mode,
- return_dict=False,
- )
-
- if guess_mode and do_classifier_free_guidance:
- # Infered ControlNet only for the conditional batch.
- # To apply the output of ControlNet to both the unconditional and conditional batches,
- # add 0 to the unconditional batch to keep it unchanged.
- down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
- mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
-
- # predict the noise residual
- noise_pred = self.unet(
- latent_model_input,
- t,
- encoder_hidden_states=prompt_embeds,
- cross_attention_kwargs=cross_attention_kwargs,
- down_block_additional_residuals=down_block_res_samples,
- mid_block_additional_residual=mid_block_res_sample,
- return_dict=False,
- )[0]
-
- # perform guidance
- if do_classifier_free_guidance:
- noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
- noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
-
- # compute the previous noisy sample x_t -> x_t-1
- latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
-
- # call the callback, if provided
- if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
- progress_bar.update()
- if callback is not None and i % callback_steps == 0:
- callback(i, t, latents)
-
- # If we do sequential model offloading, let's offload unet and controlnet
- # manually for max memory savings
- if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
- self.unet.to("cpu")
- self.controlnet.to("cpu")
- torch.cuda.empty_cache()
-
- if not output_type == "latent":
- image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
- image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
- else:
- image = latents
- has_nsfw_concept = None
-
- if has_nsfw_concept is None:
- do_denormalize = [True] * image.shape[0]
- else:
- do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
-
- image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
-
- # Offload last model to CPU
- if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
- self.final_offload_hook.offload()
-
- if not return_dict:
- return (image, has_nsfw_concept)
-
- return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/src/diffusers/utils/dummy_torch_and_transformers_objects.py b/src/diffusers/utils/dummy_torch_and_transformers_objects.py
index f3708107e82a..4c6c595c41d8 100644
--- a/src/diffusers/utils/dummy_torch_and_transformers_objects.py
+++ b/src/diffusers/utils/dummy_torch_and_transformers_objects.py
@@ -212,6 +212,36 @@ def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch", "transformers"])
+class StableDiffusionControlNetImg2ImgPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionControlNetInpaintPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
class StableDiffusionControlNetPipeline(metaclass=DummyObject):
_backends = ["torch", "transformers"]
diff --git a/tests/pipelines/controlnet/__init__.py b/tests/pipelines/controlnet/__init__.py
new file mode 100644
index 000000000000..e69de29bb2d1
diff --git a/tests/pipelines/stable_diffusion/test_stable_diffusion_controlnet.py b/tests/pipelines/controlnet/test_controlnet.py
similarity index 98%
rename from tests/pipelines/stable_diffusion/test_stable_diffusion_controlnet.py
rename to tests/pipelines/controlnet/test_controlnet.py
index bd1470f5ebd1..0453bb38e1ee 100644
--- a/tests/pipelines/stable_diffusion/test_stable_diffusion_controlnet.py
+++ b/tests/pipelines/controlnet/test_controlnet.py
@@ -34,7 +34,10 @@
from diffusers.utils.import_utils import is_xformers_available
from diffusers.utils.testing_utils import require_torch_gpu
-from ..pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_PARAMS
+from ..pipeline_params import (
+ TEXT_TO_IMAGE_BATCH_PARAMS,
+ TEXT_TO_IMAGE_PARAMS,
+)
from ..test_pipelines_common import PipelineLatentTesterMixin, PipelineTesterMixin
@@ -42,7 +45,7 @@
torch.use_deterministic_algorithms(True)
-class StableDiffusionControlNetPipelineFastTests(PipelineLatentTesterMixin, PipelineTesterMixin, unittest.TestCase):
+class ControlNetPipelineFastTests(PipelineLatentTesterMixin, PipelineTesterMixin, unittest.TestCase):
pipeline_class = StableDiffusionControlNetPipeline
params = TEXT_TO_IMAGE_PARAMS
batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
@@ -155,6 +158,7 @@ class StableDiffusionMultiControlNetPipelineFastTests(PipelineTesterMixin, unitt
pipeline_class = StableDiffusionControlNetPipeline
params = TEXT_TO_IMAGE_PARAMS
batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
+ image_params = frozenset([]) # TO_DO: add image_params once refactored VaeImageProcessor.preprocess
def get_dummy_components(self):
torch.manual_seed(0)
@@ -307,7 +311,7 @@ def test_save_load_optional_components(self):
@slow
@require_torch_gpu
-class StableDiffusionControlNetPipelineSlowTests(unittest.TestCase):
+class ControlNetPipelineSlowTests(unittest.TestCase):
def tearDown(self):
super().tearDown()
gc.collect()
diff --git a/tests/pipelines/controlnet/test_controlnet_img2img.py b/tests/pipelines/controlnet/test_controlnet_img2img.py
new file mode 100644
index 000000000000..b83a8af2778b
--- /dev/null
+++ b/tests/pipelines/controlnet/test_controlnet_img2img.py
@@ -0,0 +1,366 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This model implementation is heavily inspired by https://github.com/haofanwang/ControlNet-for-Diffusers/
+
+import gc
+import random
+import tempfile
+import unittest
+
+import numpy as np
+import torch
+from PIL import Image
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ ControlNetModel,
+ DDIMScheduler,
+ StableDiffusionControlNetImg2ImgPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_controlnet import MultiControlNetModel
+from diffusers.utils import floats_tensor, load_image, load_numpy, randn_tensor, slow, torch_device
+from diffusers.utils.import_utils import is_xformers_available
+from diffusers.utils.testing_utils import require_torch_gpu
+
+from ..pipeline_params import (
+ TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS,
+ TEXT_GUIDED_IMAGE_VARIATION_PARAMS,
+)
+from ..test_pipelines_common import PipelineLatentTesterMixin, PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+torch.use_deterministic_algorithms(True)
+
+
+class ControlNetImg2ImgPipelineFastTests(PipelineLatentTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionControlNetImg2ImgPipeline
+ params = TEXT_GUIDED_IMAGE_VARIATION_PARAMS - {"height", "width"}
+ batch_params = TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS
+ image_params = frozenset([]) # TO_DO: add image_params once refactored VaeImageProcessor.preprocess
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ torch.manual_seed(0)
+ controlnet = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "controlnet": controlnet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+
+ controlnet_embedder_scale_factor = 2
+ control_image = randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ )
+ image = floats_tensor(control_image.shape, rng=random.Random(seed)).to(device)
+ image = image.cpu().permute(0, 2, 3, 1)[0]
+ image = Image.fromarray(np.uint8(image)).convert("RGB").resize((64, 64))
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ "image": image,
+ "control_image": control_image,
+ }
+
+ return inputs
+
+ def test_attention_slicing_forward_pass(self):
+ return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_attention_forwardGenerator_pass(self):
+ self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(expected_max_diff=2e-3)
+
+
+class StableDiffusionMultiControlNetPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionControlNetImg2ImgPipeline
+ params = TEXT_GUIDED_IMAGE_VARIATION_PARAMS - {"height", "width"}
+ batch_params = TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS
+ image_params = frozenset([]) # TO_DO: add image_params once refactored VaeImageProcessor.preprocess
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ torch.manual_seed(0)
+ controlnet1 = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ controlnet2 = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ controlnet = MultiControlNetModel([controlnet1, controlnet2])
+
+ components = {
+ "unet": unet,
+ "controlnet": controlnet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+
+ controlnet_embedder_scale_factor = 2
+
+ control_image = [
+ randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ ),
+ randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ ),
+ ]
+
+ image = floats_tensor(control_image[0].shape, rng=random.Random(seed)).to(device)
+ image = image.cpu().permute(0, 2, 3, 1)[0]
+ image = Image.fromarray(np.uint8(image)).convert("RGB").resize((64, 64))
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ "image": image,
+ "control_image": control_image,
+ }
+
+ return inputs
+
+ def test_attention_slicing_forward_pass(self):
+ return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_attention_forwardGenerator_pass(self):
+ self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(expected_max_diff=2e-3)
+
+ def test_save_pretrained_raise_not_implemented_exception(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ with tempfile.TemporaryDirectory() as tmpdir:
+ try:
+ # save_pretrained is not implemented for Multi-ControlNet
+ pipe.save_pretrained(tmpdir)
+ except NotImplementedError:
+ pass
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_float16(self):
+ ...
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_local(self):
+ ...
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_optional_components(self):
+ ...
+
+
+@slow
+@require_torch_gpu
+class ControlNetImg2ImgPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_canny(self):
+ controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
+
+ pipe = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
+ )
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ prompt = "evil space-punk bird"
+ control_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
+ ).resize((512, 512))
+ image = load_image(
+ "https://huggingface.co/lllyasviel/sd-controlnet-canny/resolve/main/images/bird.png"
+ ).resize((512, 512))
+
+ output = pipe(
+ prompt,
+ image,
+ control_image=control_image,
+ generator=generator,
+ output_type="np",
+ num_inference_steps=50,
+ strength=0.6,
+ )
+
+ image = output.images[0]
+
+ assert image.shape == (512, 512, 3)
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/img2img.npy"
+ )
+
+ assert np.abs(expected_image - image).max() < 9e-2
diff --git a/tests/pipelines/controlnet/test_controlnet_inpaint.py b/tests/pipelines/controlnet/test_controlnet_inpaint.py
new file mode 100644
index 000000000000..786b0e608ef0
--- /dev/null
+++ b/tests/pipelines/controlnet/test_controlnet_inpaint.py
@@ -0,0 +1,379 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This model implementation is heavily based on:
+
+import gc
+import random
+import tempfile
+import unittest
+
+import numpy as np
+import torch
+from PIL import Image
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ ControlNetModel,
+ DDIMScheduler,
+ StableDiffusionControlNetInpaintPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_controlnet import MultiControlNetModel
+from diffusers.utils import floats_tensor, load_image, load_numpy, randn_tensor, slow, torch_device
+from diffusers.utils.import_utils import is_xformers_available
+from diffusers.utils.testing_utils import require_torch_gpu
+
+from ..pipeline_params import (
+ TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS,
+ TEXT_GUIDED_IMAGE_INPAINTING_PARAMS,
+)
+from ..test_pipelines_common import PipelineLatentTesterMixin, PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+torch.use_deterministic_algorithms(True)
+
+
+class ControlNetInpaintPipelineFastTests(PipelineLatentTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionControlNetInpaintPipeline
+ params = TEXT_GUIDED_IMAGE_INPAINTING_PARAMS
+ batch_params = TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS
+ image_params = frozenset([])
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=9,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ torch.manual_seed(0)
+ controlnet = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "controlnet": controlnet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+
+ controlnet_embedder_scale_factor = 2
+ control_image = randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ )
+ init_image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)).to(device)
+ init_image = init_image.cpu().permute(0, 2, 3, 1)[0]
+
+ image = Image.fromarray(np.uint8(init_image)).convert("RGB").resize((64, 64))
+ mask_image = Image.fromarray(np.uint8(init_image + 4)).convert("RGB").resize((64, 64))
+
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ "image": image,
+ "mask_image": mask_image,
+ "control_image": control_image,
+ }
+
+ return inputs
+
+ def test_attention_slicing_forward_pass(self):
+ return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_attention_forwardGenerator_pass(self):
+ self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(expected_max_diff=2e-3)
+
+
+class MultiControlNetInpaintPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionControlNetInpaintPipeline
+ params = TEXT_GUIDED_IMAGE_INPAINTING_PARAMS
+ batch_params = TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=9,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ torch.manual_seed(0)
+ controlnet1 = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ controlnet2 = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ controlnet = MultiControlNetModel([controlnet1, controlnet2])
+
+ components = {
+ "unet": unet,
+ "controlnet": controlnet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+
+ controlnet_embedder_scale_factor = 2
+
+ control_image = [
+ randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ ),
+ randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ ),
+ ]
+ init_image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)).to(device)
+ init_image = init_image.cpu().permute(0, 2, 3, 1)[0]
+
+ image = Image.fromarray(np.uint8(init_image)).convert("RGB").resize((64, 64))
+ mask_image = Image.fromarray(np.uint8(init_image + 4)).convert("RGB").resize((64, 64))
+
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ "image": image,
+ "mask_image": mask_image,
+ "control_image": control_image,
+ }
+
+ return inputs
+
+ def test_attention_slicing_forward_pass(self):
+ return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_attention_forwardGenerator_pass(self):
+ self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(expected_max_diff=2e-3)
+
+ def test_save_pretrained_raise_not_implemented_exception(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ with tempfile.TemporaryDirectory() as tmpdir:
+ try:
+ # save_pretrained is not implemented for Multi-ControlNet
+ pipe.save_pretrained(tmpdir)
+ except NotImplementedError:
+ pass
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_float16(self):
+ ...
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_local(self):
+ ...
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_optional_components(self):
+ ...
+
+
+@slow
+@require_torch_gpu
+class ControlNetInpaintPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_canny(self):
+ controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
+
+ pipe = StableDiffusionControlNetInpaintPipeline.from_pretrained(
+ "runwayml/stable-diffusion-inpainting", safety_checker=None, controlnet=controlnet
+ )
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ image = load_image(
+ "https://huggingface.co/lllyasviel/sd-controlnet-canny/resolve/main/images/bird.png"
+ ).resize((512, 512))
+
+ mask_image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint/input_bench_mask.png"
+ ).resize((512, 512))
+
+ prompt = "pitch black hole"
+
+ control_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
+ ).resize((512, 512))
+
+ output = pipe(
+ prompt,
+ image=image,
+ mask_image=mask_image,
+ control_image=control_image,
+ generator=generator,
+ output_type="np",
+ num_inference_steps=3,
+ )
+
+ image = output.images[0]
+
+ assert image.shape == (512, 512, 3)
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/inpaint.npy"
+ )
+
+ assert np.abs(expected_image - image).max() < 9e-2
diff --git a/tests/pipelines/stable_diffusion/test_stable_diffusion_flax_controlnet.py b/tests/pipelines/controlnet/test_flax_controlnet.py
similarity index 98%
rename from tests/pipelines/stable_diffusion/test_stable_diffusion_flax_controlnet.py
rename to tests/pipelines/controlnet/test_flax_controlnet.py
index 268c01320177..4ad75b407acc 100644
--- a/tests/pipelines/stable_diffusion/test_stable_diffusion_flax_controlnet.py
+++ b/tests/pipelines/controlnet/test_flax_controlnet.py
@@ -30,7 +30,7 @@
@slow
@require_flax
-class FlaxStableDiffusionControlNetPipelineIntegrationTests(unittest.TestCase):
+class FlaxControlNetPipelineIntegrationTests(unittest.TestCase):
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
diff --git a/tests/pipelines/stable_diffusion/test_stable_diffusion_image_variation.py b/tests/pipelines/stable_diffusion/test_stable_diffusion_image_variation.py
index 8c27a568d24d..0ce55ae78ae0 100644
--- a/tests/pipelines/stable_diffusion/test_stable_diffusion_image_variation.py
+++ b/tests/pipelines/stable_diffusion/test_stable_diffusion_image_variation.py
@@ -46,9 +46,8 @@ class StableDiffusionImageVariationPipelineFastTests(
pipeline_class = StableDiffusionImageVariationPipeline
params = IMAGE_VARIATION_PARAMS
batch_params = IMAGE_VARIATION_BATCH_PARAMS
- image_params = frozenset(
- []
- ) # TO-DO: update image_params once pipeline is refactored with VaeImageProcessor.preprocess
+ image_params = frozenset([])
+ # TO-DO: update image_params once pipeline is refactored with VaeImageProcessor.preprocess
def get_dummy_components(self):
torch.manual_seed(0)
diff --git a/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py b/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py
index cdf138c4e178..a215e4da6697 100644
--- a/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py
+++ b/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py
@@ -47,9 +47,8 @@ class StableDiffusionInpaintPipelineFastTests(PipelineLatentTesterMixin, Pipelin
pipeline_class = StableDiffusionInpaintPipeline
params = TEXT_GUIDED_IMAGE_INPAINTING_PARAMS
batch_params = TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS
- image_params = frozenset(
- []
- ) # TO-DO: update image_params once pipeline is refactored with VaeImageProcessor.preprocess
+ image_params = frozenset([])
+ # TO-DO: update image_params once pipeline is refactored with VaeImageProcessor.preprocess
def get_dummy_components(self):
torch.manual_seed(0)
|
## StableDiffusionControlNetPipeline
[[autodoc]] StableDiffusionControlNetPipeline
@@ -329,6 +332,30 @@ All checkpoints can be found under the authors' namespace [lllyasviel](https://h
- disable_xformers_memory_efficient_attention
- load_textual_inversion
+## StableDiffusionControlNetImg2ImgPipeline
+[[autodoc]] StableDiffusionControlNetImg2ImgPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+ - load_textual_inversion
+
+## StableDiffusionControlNetInpaintPipeline
+[[autodoc]] StableDiffusionControlNetInpaintPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+ - load_textual_inversion
+
## FlaxStableDiffusionControlNetPipeline
[[autodoc]] FlaxStableDiffusionControlNetPipeline
- all
diff --git a/docs/source/en/api/pipelines/overview.mdx b/docs/source/en/api/pipelines/overview.mdx
index 91716784f8fe..2b2f95590016 100644
--- a/docs/source/en/api/pipelines/overview.mdx
+++ b/docs/source/en/api/pipelines/overview.mdx
@@ -46,7 +46,7 @@ available a colab notebook to directly try them out.
|---|---|:---:|:---:|
| [alt_diffusion](./alt_diffusion) | [**AltDiffusion**](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation | -
| [audio_diffusion](./audio_diffusion) | [**Audio Diffusion**](https://github.com/teticio/audio_diffusion.git) | Unconditional Audio Generation |
-| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb)
+| [controlnet](./api/pipelines/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb)
| [cycle_diffusion](./cycle_diffusion) | [**Cycle Diffusion**](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
| [dance_diffusion](./dance_diffusion) | [**Dance Diffusion**](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
| [ddpm](./ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
diff --git a/docs/source/en/index.mdx b/docs/source/en/index.mdx
index 46a985ac2f8d..66548663827a 100644
--- a/docs/source/en/index.mdx
+++ b/docs/source/en/index.mdx
@@ -53,7 +53,7 @@ The library has three main components:
|---|---|:---:|
| [alt_diffusion](./api/pipelines/alt_diffusion) | [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
| [audio_diffusion](./api/pipelines/audio_diffusion) | [Audio Diffusion](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation |
-| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation |
+| [controlnet](./api/pipelines/controlnet) | [Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation |
| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
| [dance_diffusion](./api/pipelines/dance_diffusion) | [Dance Diffusion](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
| [ddpm](./api/pipelines/ddpm) | [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
diff --git a/src/diffusers/__init__.py b/src/diffusers/__init__.py
index a8293ea77fef..0d48a16b6216 100644
--- a/src/diffusers/__init__.py
+++ b/src/diffusers/__init__.py
@@ -132,6 +132,8 @@
PaintByExamplePipeline,
SemanticStableDiffusionPipeline,
StableDiffusionAttendAndExcitePipeline,
+ StableDiffusionControlNetImg2ImgPipeline,
+ StableDiffusionControlNetInpaintPipeline,
StableDiffusionControlNetPipeline,
StableDiffusionDepth2ImgPipeline,
StableDiffusionDiffEditPipeline,
diff --git a/src/diffusers/pipeline_utils.py b/src/diffusers/pipeline_utils.py
index 5c0c2337dc04..87709d5f616c 100644
--- a/src/diffusers/pipeline_utils.py
+++ b/src/diffusers/pipeline_utils.py
@@ -17,3 +17,13 @@
# It only exists so that temporarely `from diffusers.pipelines import DiffusionPipeline` works
from .pipelines import DiffusionPipeline, ImagePipelineOutput # noqa: F401
+from .utils import deprecate
+
+
+deprecate(
+ "pipelines_utils",
+ "0.22.0",
+ "Importing `DiffusionPipeline` or `ImagePipelineOutput` from diffusers.pipeline_utils is deprecated. Please import from diffusers.pipelines.pipeline_utils instead.",
+ standard_warn=False,
+ stacklevel=3,
+)
diff --git a/src/diffusers/pipelines/__init__.py b/src/diffusers/pipelines/__init__.py
index 3cddad4a6b26..9b44f4e5eb14 100644
--- a/src/diffusers/pipelines/__init__.py
+++ b/src/diffusers/pipelines/__init__.py
@@ -44,6 +44,11 @@
else:
from .alt_diffusion import AltDiffusionImg2ImgPipeline, AltDiffusionPipeline
from .audioldm import AudioLDMPipeline
+ from .controlnet import (
+ StableDiffusionControlNetImg2ImgPipeline,
+ StableDiffusionControlNetInpaintPipeline,
+ StableDiffusionControlNetPipeline,
+ )
from .deepfloyd_if import (
IFImg2ImgPipeline,
IFImg2ImgSuperResolutionPipeline,
@@ -58,7 +63,6 @@
from .stable_diffusion import (
CycleDiffusionPipeline,
StableDiffusionAttendAndExcitePipeline,
- StableDiffusionControlNetPipeline,
StableDiffusionDepth2ImgPipeline,
StableDiffusionDiffEditPipeline,
StableDiffusionImageVariationPipeline,
@@ -133,8 +137,8 @@
except OptionalDependencyNotAvailable:
from ..utils.dummy_flax_and_transformers_objects import * # noqa F403
else:
+ from .controlnet import FlaxStableDiffusionControlNetPipeline
from .stable_diffusion import (
- FlaxStableDiffusionControlNetPipeline,
FlaxStableDiffusionImg2ImgPipeline,
FlaxStableDiffusionInpaintPipeline,
FlaxStableDiffusionPipeline,
diff --git a/src/diffusers/pipelines/controlnet/__init__.py b/src/diffusers/pipelines/controlnet/__init__.py
new file mode 100644
index 000000000000..76ab63bdb116
--- /dev/null
+++ b/src/diffusers/pipelines/controlnet/__init__.py
@@ -0,0 +1,22 @@
+from ...utils import (
+ OptionalDependencyNotAvailable,
+ is_flax_available,
+ is_torch_available,
+ is_transformers_available,
+)
+
+
+try:
+ if not (is_transformers_available() and is_torch_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils.dummy_torch_and_transformers_objects import * # noqa F403
+else:
+ from .multicontrolnet import MultiControlNetModel
+ from .pipeline_controlnet import StableDiffusionControlNetPipeline
+ from .pipeline_controlnet_img2img import StableDiffusionControlNetImg2ImgPipeline
+ from .pipeline_controlnet_inpaint import StableDiffusionControlNetInpaintPipeline
+
+
+if is_transformers_available() and is_flax_available():
+ from .pipeline_flax_controlnet import FlaxStableDiffusionControlNetPipeline
diff --git a/src/diffusers/pipelines/controlnet/multicontrolnet.py b/src/diffusers/pipelines/controlnet/multicontrolnet.py
new file mode 100644
index 000000000000..91d40b20124c
--- /dev/null
+++ b/src/diffusers/pipelines/controlnet/multicontrolnet.py
@@ -0,0 +1,66 @@
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import torch
+from torch import nn
+
+from ...models.controlnet import ControlNetModel, ControlNetOutput
+from ...models.modeling_utils import ModelMixin
+
+
+class MultiControlNetModel(ModelMixin):
+ r"""
+ Multiple `ControlNetModel` wrapper class for Multi-ControlNet
+
+ This module is a wrapper for multiple instances of the `ControlNetModel`. The `forward()` API is designed to be
+ compatible with `ControlNetModel`.
+
+ Args:
+ controlnets (`List[ControlNetModel]`):
+ Provides additional conditioning to the unet during the denoising process. You must set multiple
+ `ControlNetModel` as a list.
+ """
+
+ def __init__(self, controlnets: Union[List[ControlNetModel], Tuple[ControlNetModel]]):
+ super().__init__()
+ self.nets = nn.ModuleList(controlnets)
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[torch.Tensor, float, int],
+ encoder_hidden_states: torch.Tensor,
+ controlnet_cond: List[torch.tensor],
+ conditioning_scale: List[float],
+ class_labels: Optional[torch.Tensor] = None,
+ timestep_cond: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ guess_mode: bool = False,
+ return_dict: bool = True,
+ ) -> Union[ControlNetOutput, Tuple]:
+ for i, (image, scale, controlnet) in enumerate(zip(controlnet_cond, conditioning_scale, self.nets)):
+ down_samples, mid_sample = controlnet(
+ sample,
+ timestep,
+ encoder_hidden_states,
+ image,
+ scale,
+ class_labels,
+ timestep_cond,
+ attention_mask,
+ cross_attention_kwargs,
+ guess_mode,
+ return_dict,
+ )
+
+ # merge samples
+ if i == 0:
+ down_block_res_samples, mid_block_res_sample = down_samples, mid_sample
+ else:
+ down_block_res_samples = [
+ samples_prev + samples_curr
+ for samples_prev, samples_curr in zip(down_block_res_samples, down_samples)
+ ]
+ mid_block_res_sample += mid_sample
+
+ return down_block_res_samples, mid_block_res_sample
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet.py
new file mode 100644
index 000000000000..8a2ffbbff171
--- /dev/null
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet.py
@@ -0,0 +1,1035 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import inspect
+import os
+import warnings
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import PIL.Image
+import torch
+import torch.nn.functional as F
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...image_processor import VaeImageProcessor
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, ControlNetModel, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import (
+ PIL_INTERPOLATION,
+ is_accelerate_available,
+ is_accelerate_version,
+ is_compiled_module,
+ logging,
+ randn_tensor,
+ replace_example_docstring,
+)
+from ..pipeline_utils import DiffusionPipeline
+from ..stable_diffusion import StableDiffusionPipelineOutput
+from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
+from .multicontrolnet import MultiControlNetModel
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> # !pip install opencv-python transformers accelerate
+ >>> from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
+ >>> from diffusers.utils import load_image
+ >>> import numpy as np
+ >>> import torch
+
+ >>> import cv2
+ >>> from PIL import Image
+
+ >>> # download an image
+ >>> image = load_image(
+ ... "https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
+ ... )
+ >>> image = np.array(image)
+
+ >>> # get canny image
+ >>> image = cv2.Canny(image, 100, 200)
+ >>> image = image[:, :, None]
+ >>> image = np.concatenate([image, image, image], axis=2)
+ >>> canny_image = Image.fromarray(image)
+
+ >>> # load control net and stable diffusion v1-5
+ >>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
+ >>> pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
+ ... )
+
+ >>> # speed up diffusion process with faster scheduler and memory optimization
+ >>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+ >>> # remove following line if xformers is not installed
+ >>> pipe.enable_xformers_memory_efficient_attention()
+
+ >>> pipe.enable_model_cpu_offload()
+
+ >>> # generate image
+ >>> generator = torch.manual_seed(0)
+ >>> image = pipe(
+ ... "futuristic-looking woman", num_inference_steps=20, generator=generator, image=canny_image
+ ... ).images[0]
+ ```
+"""
+
+
+class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ In addition the pipeline inherits the following loading methods:
+ - *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
+ Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets
+ as a list, the outputs from each ControlNet are added together to create one combined additional
+ conditioning.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ if isinstance(controlnet, (list, tuple)):
+ controlnet = MultiControlNetModel(controlnet)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ controlnet=controlnet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
+ several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.controlnet]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ # the safety checker can offload the vae again
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # control net hook has be manually offloaded as it alternates with unet
+ cpu_offload_with_hook(self.controlnet, device)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is None:
+ has_nsfw_concept = None
+ else:
+ if torch.is_tensor(image):
+ feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
+ else:
+ feature_extractor_input = self.image_processor.numpy_to_pil(image)
+ safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ warnings.warn(
+ "The decode_latents method is deprecated and will be removed in a future version. Please"
+ " use VaeImageProcessor instead",
+ FutureWarning,
+ )
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents, return_dict=False)[0]
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ image,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ controlnet_conditioning_scale=1.0,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # `prompt` needs more sophisticated handling when there are multiple
+ # conditionings.
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if isinstance(prompt, list):
+ logger.warning(
+ f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
+ " prompts. The conditionings will be fixed across the prompts."
+ )
+
+ # Check `image`
+ is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
+ self.controlnet, torch._dynamo.eval_frame.OptimizedModule
+ )
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ self.check_image(image, prompt, prompt_embeds)
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if not isinstance(image, list):
+ raise TypeError("For multiple controlnets: `image` must be type `list`")
+
+ # When `image` is a nested list:
+ # (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
+ elif any(isinstance(i, list) for i in image):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif len(image) != len(self.controlnet.nets):
+ raise ValueError(
+ "For multiple controlnets: `image` must have the same length as the number of controlnets."
+ )
+
+ for image_ in image:
+ self.check_image(image_, prompt, prompt_embeds)
+ else:
+ assert False
+
+ # Check `controlnet_conditioning_scale`
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ if not isinstance(controlnet_conditioning_scale, float):
+ raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if isinstance(controlnet_conditioning_scale, list):
+ if any(isinstance(i, list) for i in controlnet_conditioning_scale):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
+ self.controlnet.nets
+ ):
+ raise ValueError(
+ "For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
+ " the same length as the number of controlnets"
+ )
+ else:
+ assert False
+
+ def check_image(self, image, prompt, prompt_embeds):
+ image_is_pil = isinstance(image, PIL.Image.Image)
+ image_is_tensor = isinstance(image, torch.Tensor)
+ image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
+ image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
+
+ if not image_is_pil and not image_is_tensor and not image_is_pil_list and not image_is_tensor_list:
+ raise TypeError(
+ "image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
+ )
+
+ if image_is_pil:
+ image_batch_size = 1
+ elif image_is_tensor:
+ image_batch_size = image.shape[0]
+ elif image_is_pil_list:
+ image_batch_size = len(image)
+ elif image_is_tensor_list:
+ image_batch_size = len(image)
+
+ if prompt is not None and isinstance(prompt, str):
+ prompt_batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ prompt_batch_size = len(prompt)
+ elif prompt_embeds is not None:
+ prompt_batch_size = prompt_embeds.shape[0]
+
+ if image_batch_size != 1 and image_batch_size != prompt_batch_size:
+ raise ValueError(
+ f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
+ )
+
+ def prepare_image(
+ self,
+ image,
+ width,
+ height,
+ batch_size,
+ num_images_per_prompt,
+ device,
+ dtype,
+ do_classifier_free_guidance=False,
+ guess_mode=False,
+ ):
+ if not isinstance(image, torch.Tensor):
+ if isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ images = []
+
+ for image_ in image:
+ image_ = image_.convert("RGB")
+ image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
+ image_ = np.array(image_)
+ image_ = image_[None, :]
+ images.append(image_)
+
+ image = images
+
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+
+ image_batch_size = image.shape[0]
+
+ if image_batch_size == 1:
+ repeat_by = batch_size
+ else:
+ # image batch size is the same as prompt batch size
+ repeat_by = num_images_per_prompt
+
+ image = image.repeat_interleave(repeat_by, dim=0)
+
+ image = image.to(device=device, dtype=dtype)
+
+ if do_classifier_free_guidance and not guess_mode:
+ image = torch.cat([image] * 2)
+
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ def _default_height_width(self, height, width, image):
+ # NOTE: It is possible that a list of images have different
+ # dimensions for each image, so just checking the first image
+ # is not _exactly_ correct, but it is simple.
+ while isinstance(image, list):
+ image = image[0]
+
+ if height is None:
+ if isinstance(image, PIL.Image.Image):
+ height = image.height
+ elif isinstance(image, torch.Tensor):
+ height = image.shape[2]
+
+ height = (height // 8) * 8 # round down to nearest multiple of 8
+
+ if width is None:
+ if isinstance(image, PIL.Image.Image):
+ width = image.width
+ elif isinstance(image, torch.Tensor):
+ width = image.shape[3]
+
+ width = (width // 8) * 8 # round down to nearest multiple of 8
+
+ return height, width
+
+ # override DiffusionPipeline
+ def save_pretrained(
+ self,
+ save_directory: Union[str, os.PathLike],
+ safe_serialization: bool = False,
+ variant: Optional[str] = None,
+ ):
+ if isinstance(self.controlnet, ControlNetModel):
+ super().save_pretrained(save_directory, safe_serialization, variant)
+ else:
+ raise NotImplementedError("Currently, the `save_pretrained()` is not implemented for Multi-ControlNet.")
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ image: Union[torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
+ guess_mode: bool = False,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`,
+ `List[List[torch.FloatTensor]]`, or `List[List[PIL.Image.Image]]`):
+ The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
+ the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
+ also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
+ height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
+ specified in init, images must be passed as a list such that each element of the list can be correctly
+ batched for input to a single controlnet.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+ controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
+ The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
+ to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
+ corresponding scale as a list.
+ guess_mode (`bool`, *optional*, defaults to `False`):
+ In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
+ you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height, width = self._default_height_width(height, width, image)
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ image,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ prompt_embeds,
+ negative_prompt_embeds,
+ controlnet_conditioning_scale,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
+
+ if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
+ controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
+
+ global_pool_conditions = (
+ controlnet.config.global_pool_conditions
+ if isinstance(controlnet, ControlNetModel)
+ else controlnet.nets[0].config.global_pool_conditions
+ )
+ guess_mode = guess_mode or global_pool_conditions
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare image
+ if isinstance(controlnet, ControlNetModel):
+ image = self.prepare_image(
+ image=image,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+ elif isinstance(controlnet, MultiControlNetModel):
+ images = []
+
+ for image_ in image:
+ image_ = self.prepare_image(
+ image=image_,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+
+ images.append(image_)
+
+ image = images
+ else:
+ assert False
+
+ # 5. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 6. Prepare latent variables
+ num_channels_latents = self.unet.config.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # controlnet(s) inference
+ if guess_mode and do_classifier_free_guidance:
+ # Infer ControlNet only for the conditional batch.
+ controlnet_latent_model_input = latents
+ controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
+ else:
+ controlnet_latent_model_input = latent_model_input
+ controlnet_prompt_embeds = prompt_embeds
+
+ down_block_res_samples, mid_block_res_sample = self.controlnet(
+ controlnet_latent_model_input,
+ t,
+ encoder_hidden_states=controlnet_prompt_embeds,
+ controlnet_cond=image,
+ conditioning_scale=controlnet_conditioning_scale,
+ guess_mode=guess_mode,
+ return_dict=False,
+ )
+
+ if guess_mode and do_classifier_free_guidance:
+ # Infered ControlNet only for the conditional batch.
+ # To apply the output of ControlNet to both the unconditional and conditional batches,
+ # add 0 to the unconditional batch to keep it unchanged.
+ down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
+ mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ down_block_additional_residuals=down_block_res_samples,
+ mid_block_additional_residual=mid_block_res_sample,
+ return_dict=False,
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # If we do sequential model offloading, let's offload unet and controlnet
+ # manually for max memory savings
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.unet.to("cpu")
+ self.controlnet.to("cpu")
+ torch.cuda.empty_cache()
+
+ if not output_type == "latent":
+ image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+ else:
+ image = latents
+ has_nsfw_concept = None
+
+ if has_nsfw_concept is None:
+ do_denormalize = [True] * image.shape[0]
+ else:
+ do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
+
+ image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet_img2img.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet_img2img.py
new file mode 100644
index 000000000000..cb5492790353
--- /dev/null
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet_img2img.py
@@ -0,0 +1,1113 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import inspect
+import os
+import warnings
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import PIL.Image
+import torch
+import torch.nn.functional as F
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...image_processor import VaeImageProcessor
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, ControlNetModel, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import (
+ PIL_INTERPOLATION,
+ deprecate,
+ is_accelerate_available,
+ is_accelerate_version,
+ is_compiled_module,
+ logging,
+ randn_tensor,
+ replace_example_docstring,
+)
+from ..pipeline_utils import DiffusionPipeline
+from ..stable_diffusion import StableDiffusionPipelineOutput
+from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
+from .multicontrolnet import MultiControlNetModel
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> # !pip install opencv-python transformers accelerate
+ >>> from diffusers import StableDiffusionControlNetImg2ImgPipeline, ControlNetModel, UniPCMultistepScheduler
+ >>> from diffusers.utils import load_image
+ >>> import numpy as np
+ >>> import torch
+
+ >>> import cv2
+ >>> from PIL import Image
+
+ >>> # download an image
+ >>> image = load_image(
+ ... "https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
+ ... )
+ >>> np_image = np.array(image)
+
+ >>> # get canny image
+ >>> np_image = cv2.Canny(np_image, 100, 200)
+ >>> np_image = np_image[:, :, None]
+ >>> np_image = np.concatenate([np_image, np_image, np_image], axis=2)
+ >>> canny_image = Image.fromarray(np_image)
+
+ >>> # load control net and stable diffusion v1-5
+ >>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
+ >>> pipe = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
+ ... )
+
+ >>> # speed up diffusion process with faster scheduler and memory optimization
+ >>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+ >>> pipe.enable_model_cpu_offload()
+
+ >>> # generate image
+ >>> generator = torch.manual_seed(0)
+ >>> image = pipe(
+ ... "futuristic-looking woman",
+ ... num_inference_steps=20,
+ ... generator=generator,
+ ... image=image,
+ ... control_image=canny_image,
+ ... ).images[0]
+ ```
+"""
+
+
+def prepare_image(image):
+ if isinstance(image, torch.Tensor):
+ # Batch single image
+ if image.ndim == 3:
+ image = image.unsqueeze(0)
+
+ image = image.to(dtype=torch.float32)
+ else:
+ # preprocess image
+ if isinstance(image, (PIL.Image.Image, np.ndarray)):
+ image = [image]
+
+ if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
+ image = [np.array(i.convert("RGB"))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ elif isinstance(image, list) and isinstance(image[0], np.ndarray):
+ image = np.concatenate([i[None, :] for i in image], axis=0)
+
+ image = image.transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
+
+ return image
+
+
+class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ In addition the pipeline inherits the following loading methods:
+ - *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
+ Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets
+ as a list, the outputs from each ControlNet are added together to create one combined additional
+ conditioning.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ if isinstance(controlnet, (list, tuple)):
+ controlnet = MultiControlNetModel(controlnet)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ controlnet=controlnet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
+ several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.controlnet]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ # the safety checker can offload the vae again
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # control net hook has be manually offloaded as it alternates with unet
+ cpu_offload_with_hook(self.controlnet, device)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is None:
+ has_nsfw_concept = None
+ else:
+ if torch.is_tensor(image):
+ feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
+ else:
+ feature_extractor_input = self.image_processor.numpy_to_pil(image)
+ safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ warnings.warn(
+ "The decode_latents method is deprecated and will be removed in a future version. Please"
+ " use VaeImageProcessor instead",
+ FutureWarning,
+ )
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents, return_dict=False)[0]
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ image,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ controlnet_conditioning_scale=1.0,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # `prompt` needs more sophisticated handling when there are multiple
+ # conditionings.
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if isinstance(prompt, list):
+ logger.warning(
+ f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
+ " prompts. The conditionings will be fixed across the prompts."
+ )
+
+ # Check `image`
+ is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
+ self.controlnet, torch._dynamo.eval_frame.OptimizedModule
+ )
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ self.check_image(image, prompt, prompt_embeds)
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if not isinstance(image, list):
+ raise TypeError("For multiple controlnets: `image` must be type `list`")
+
+ # When `image` is a nested list:
+ # (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
+ elif any(isinstance(i, list) for i in image):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif len(image) != len(self.controlnet.nets):
+ raise ValueError(
+ "For multiple controlnets: `image` must have the same length as the number of controlnets."
+ )
+
+ for image_ in image:
+ self.check_image(image_, prompt, prompt_embeds)
+ else:
+ assert False
+
+ # Check `controlnet_conditioning_scale`
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ if not isinstance(controlnet_conditioning_scale, float):
+ raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if isinstance(controlnet_conditioning_scale, list):
+ if any(isinstance(i, list) for i in controlnet_conditioning_scale):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
+ self.controlnet.nets
+ ):
+ raise ValueError(
+ "For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
+ " the same length as the number of controlnets"
+ )
+ else:
+ assert False
+
+ def check_image(self, image, prompt, prompt_embeds):
+ image_is_pil = isinstance(image, PIL.Image.Image)
+ image_is_tensor = isinstance(image, torch.Tensor)
+ image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
+ image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
+
+ if not image_is_pil and not image_is_tensor and not image_is_pil_list and not image_is_tensor_list:
+ raise TypeError(
+ "image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
+ )
+
+ if image_is_pil:
+ image_batch_size = 1
+ elif image_is_tensor:
+ image_batch_size = image.shape[0]
+ elif image_is_pil_list:
+ image_batch_size = len(image)
+ elif image_is_tensor_list:
+ image_batch_size = len(image)
+
+ if prompt is not None and isinstance(prompt, str):
+ prompt_batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ prompt_batch_size = len(prompt)
+ elif prompt_embeds is not None:
+ prompt_batch_size = prompt_embeds.shape[0]
+
+ if image_batch_size != 1 and image_batch_size != prompt_batch_size:
+ raise ValueError(
+ f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
+ )
+
+ # Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.prepare_image
+ def prepare_control_image(
+ self,
+ image,
+ width,
+ height,
+ batch_size,
+ num_images_per_prompt,
+ device,
+ dtype,
+ do_classifier_free_guidance=False,
+ guess_mode=False,
+ ):
+ if not isinstance(image, torch.Tensor):
+ if isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ images = []
+
+ for image_ in image:
+ image_ = image_.convert("RGB")
+ image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
+ image_ = np.array(image_)
+ image_ = image_[None, :]
+ images.append(image_)
+
+ image = images
+
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+
+ image_batch_size = image.shape[0]
+
+ if image_batch_size == 1:
+ repeat_by = batch_size
+ else:
+ # image batch size is the same as prompt batch size
+ repeat_by = num_images_per_prompt
+
+ image = image.repeat_interleave(repeat_by, dim=0)
+
+ image = image.to(device=device, dtype=dtype)
+
+ if do_classifier_free_guidance and not guess_mode:
+ image = torch.cat([image] * 2)
+
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.get_timesteps
+ def get_timesteps(self, num_inference_steps, strength, device):
+ # get the original timestep using init_timestep
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+
+ t_start = max(num_inference_steps - init_timestep, 0)
+ timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
+
+ return timesteps, num_inference_steps - t_start
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.prepare_latents
+ def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None):
+ if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
+ raise ValueError(
+ f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
+ )
+
+ image = image.to(device=device, dtype=dtype)
+
+ batch_size = batch_size * num_images_per_prompt
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if isinstance(generator, list):
+ init_latents = [
+ self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
+ ]
+ init_latents = torch.cat(init_latents, dim=0)
+ else:
+ init_latents = self.vae.encode(image).latent_dist.sample(generator)
+
+ init_latents = self.vae.config.scaling_factor * init_latents
+
+ if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
+ # expand init_latents for batch_size
+ deprecation_message = (
+ f"You have passed {batch_size} text prompts (`prompt`), but only {init_latents.shape[0]} initial"
+ " images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
+ " that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
+ " your script to pass as many initial images as text prompts to suppress this warning."
+ )
+ deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
+ additional_image_per_prompt = batch_size // init_latents.shape[0]
+ init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
+ elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
+ raise ValueError(
+ f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
+ )
+ else:
+ init_latents = torch.cat([init_latents], dim=0)
+
+ shape = init_latents.shape
+ noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+
+ # get latents
+ init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
+ latents = init_latents
+
+ return latents
+
+ def _default_height_width(self, height, width, image):
+ # NOTE: It is possible that a list of images have different
+ # dimensions for each image, so just checking the first image
+ # is not _exactly_ correct, but it is simple.
+ while isinstance(image, list):
+ image = image[0]
+
+ if height is None:
+ if isinstance(image, PIL.Image.Image):
+ height = image.height
+ elif isinstance(image, torch.Tensor):
+ height = image.shape[2]
+
+ height = (height // 8) * 8 # round down to nearest multiple of 8
+
+ if width is None:
+ if isinstance(image, PIL.Image.Image):
+ width = image.width
+ elif isinstance(image, torch.Tensor):
+ width = image.shape[3]
+
+ width = (width // 8) * 8 # round down to nearest multiple of 8
+
+ return height, width
+
+ # override DiffusionPipeline
+ def save_pretrained(
+ self,
+ save_directory: Union[str, os.PathLike],
+ safe_serialization: bool = False,
+ variant: Optional[str] = None,
+ ):
+ if isinstance(self.controlnet, ControlNetModel):
+ super().save_pretrained(save_directory, safe_serialization, variant)
+ else:
+ raise NotImplementedError("Currently, the `save_pretrained()` is not implemented for Multi-ControlNet.")
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ image: Union[torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]] = None,
+ control_image: Union[
+ torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]
+ ] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ strength: float = 0.8,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ controlnet_conditioning_scale: Union[float, List[float]] = 0.8,
+ guess_mode: bool = False,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`,
+ `List[List[torch.FloatTensor]]`, or `List[List[PIL.Image.Image]]`):
+ The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
+ the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
+ also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
+ height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
+ specified in init, images must be passed as a list such that each element of the list can be correctly
+ batched for input to a single controlnet.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+ controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
+ The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
+ to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
+ corresponding scale as a list. Note that by default, we use a smaller conditioning scale for inpainting
+ than for [`~StableDiffusionControlNetPipeline.__call__`].
+ guess_mode (`bool`, *optional*, defaults to `False`):
+ In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
+ you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height, width = self._default_height_width(height, width, image)
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ control_image,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ prompt_embeds,
+ negative_prompt_embeds,
+ controlnet_conditioning_scale,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
+
+ if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
+ controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
+
+ global_pool_conditions = (
+ controlnet.config.global_pool_conditions
+ if isinstance(controlnet, ControlNetModel)
+ else controlnet.nets[0].config.global_pool_conditions
+ )
+ guess_mode = guess_mode or global_pool_conditions
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+ # 4. Prepare image, and controlnet_conditioning_image
+ image = prepare_image(image)
+
+ # 5. Prepare image
+ if isinstance(controlnet, ControlNetModel):
+ control_image = self.prepare_control_image(
+ image=control_image,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+ elif isinstance(controlnet, MultiControlNetModel):
+ control_images = []
+
+ for control_image_ in control_image:
+ control_image_ = self.prepare_control_image(
+ image=control_image_,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+
+ control_images.append(control_image_)
+
+ control_image = control_images
+ else:
+ assert False
+
+ # 5. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
+ latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
+
+ # 6. Prepare latent variables
+ latents = self.prepare_latents(
+ image,
+ latent_timestep,
+ batch_size,
+ num_images_per_prompt,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # controlnet(s) inference
+ if guess_mode and do_classifier_free_guidance:
+ # Infer ControlNet only for the conditional batch.
+ controlnet_latent_model_input = latents
+ controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
+ else:
+ controlnet_latent_model_input = latent_model_input
+ controlnet_prompt_embeds = prompt_embeds
+
+ down_block_res_samples, mid_block_res_sample = self.controlnet(
+ controlnet_latent_model_input,
+ t,
+ encoder_hidden_states=controlnet_prompt_embeds,
+ controlnet_cond=control_image,
+ conditioning_scale=controlnet_conditioning_scale,
+ guess_mode=guess_mode,
+ return_dict=False,
+ )
+
+ if guess_mode and do_classifier_free_guidance:
+ # Infered ControlNet only for the conditional batch.
+ # To apply the output of ControlNet to both the unconditional and conditional batches,
+ # add 0 to the unconditional batch to keep it unchanged.
+ down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
+ mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ down_block_additional_residuals=down_block_res_samples,
+ mid_block_additional_residual=mid_block_res_sample,
+ return_dict=False,
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # If we do sequential model offloading, let's offload unet and controlnet
+ # manually for max memory savings
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.unet.to("cpu")
+ self.controlnet.to("cpu")
+ torch.cuda.empty_cache()
+
+ if not output_type == "latent":
+ image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+ else:
+ image = latents
+ has_nsfw_concept = None
+
+ if has_nsfw_concept is None:
+ do_denormalize = [True] * image.shape[0]
+ else:
+ do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
+
+ image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint.py b/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint.py
new file mode 100644
index 000000000000..a146a1cc2908
--- /dev/null
+++ b/src/diffusers/pipelines/controlnet/pipeline_controlnet_inpaint.py
@@ -0,0 +1,1228 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This model implementation is heavily inspired by https://github.com/haofanwang/ControlNet-for-Diffusers/
+
+import inspect
+import os
+import warnings
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import PIL.Image
+import torch
+import torch.nn.functional as F
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...image_processor import VaeImageProcessor
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, ControlNetModel, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import (
+ PIL_INTERPOLATION,
+ is_accelerate_available,
+ is_accelerate_version,
+ is_compiled_module,
+ logging,
+ randn_tensor,
+ replace_example_docstring,
+)
+from ..pipeline_utils import DiffusionPipeline
+from ..stable_diffusion import StableDiffusionPipelineOutput
+from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
+from .multicontrolnet import MultiControlNetModel
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> # !pip install opencv-python transformers accelerate
+ >>> from diffusers import StableDiffusionControlNetInpaintPipeline, ControlNetModel, UniPCMultistepScheduler
+ >>> from diffusers.utils import load_image
+ >>> import numpy as np
+ >>> import torch
+
+ >>> import cv2
+ >>> from PIL import Image
+
+ >>> img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
+ >>> mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
+
+ >>> init_image = load_image(img_url).resize((512, 512))
+ >>> mask_image = load_image(mask_url).resize((512, 512))
+
+ >>> image = np.array(init_image)
+
+ >>> # get canny image
+ >>> image = cv2.Canny(image, 100, 200)
+ >>> image = image[:, :, None]
+ >>> image = np.concatenate([image, image, image], axis=2)
+ >>> canny_image = Image.fromarray(image)
+
+ >>> # load control net and stable diffusion inpainting
+ >>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
+ >>> pipe = StableDiffusionControlNetInpaintPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-inpainting", controlnet=controlnet, torch_dtype=torch.float16
+ ... )
+
+ >>> # speed up diffusion process with faster scheduler and memory optimization
+ >>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+
+ >>> pipe.enable_model_cpu_offload()
+
+ >>> # generate image
+ >>> generator = torch.manual_seed(0)
+ >>> image = pipe(
+ ... "spiderman",
+ ... num_inference_steps=30,
+ ... generator=generator,
+ ... image=init_image,
+ ... mask_image=mask_image,
+ ... control_image=canny_image,
+ ... ).images[0]
+ ```
+"""
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint.prepare_mask_and_masked_image
+def prepare_mask_and_masked_image(image, mask, height, width):
+ """
+ Prepares a pair (image, mask) to be consumed by the Stable Diffusion pipeline. This means that those inputs will be
+ converted to ``torch.Tensor`` with shapes ``batch x channels x height x width`` where ``channels`` is ``3`` for the
+ ``image`` and ``1`` for the ``mask``.
+
+ The ``image`` will be converted to ``torch.float32`` and normalized to be in ``[-1, 1]``. The ``mask`` will be
+ binarized (``mask > 0.5``) and cast to ``torch.float32`` too.
+
+ Args:
+ image (Union[np.array, PIL.Image, torch.Tensor]): The image to inpaint.
+ It can be a ``PIL.Image``, or a ``height x width x 3`` ``np.array`` or a ``channels x height x width``
+ ``torch.Tensor`` or a ``batch x channels x height x width`` ``torch.Tensor``.
+ mask (_type_): The mask to apply to the image, i.e. regions to inpaint.
+ It can be a ``PIL.Image``, or a ``height x width`` ``np.array`` or a ``1 x height x width``
+ ``torch.Tensor`` or a ``batch x 1 x height x width`` ``torch.Tensor``.
+
+
+ Raises:
+ ValueError: ``torch.Tensor`` images should be in the ``[-1, 1]`` range. ValueError: ``torch.Tensor`` mask
+ should be in the ``[0, 1]`` range. ValueError: ``mask`` and ``image`` should have the same spatial dimensions.
+ TypeError: ``mask`` is a ``torch.Tensor`` but ``image`` is not
+ (ot the other way around).
+
+ Returns:
+ tuple[torch.Tensor]: The pair (mask, masked_image) as ``torch.Tensor`` with 4
+ dimensions: ``batch x channels x height x width``.
+ """
+
+ if image is None:
+ raise ValueError("`image` input cannot be undefined.")
+
+ if mask is None:
+ raise ValueError("`mask_image` input cannot be undefined.")
+
+ if isinstance(image, torch.Tensor):
+ if not isinstance(mask, torch.Tensor):
+ raise TypeError(f"`image` is a torch.Tensor but `mask` (type: {type(mask)} is not")
+
+ # Batch single image
+ if image.ndim == 3:
+ assert image.shape[0] == 3, "Image outside a batch should be of shape (3, H, W)"
+ image = image.unsqueeze(0)
+
+ # Batch and add channel dim for single mask
+ if mask.ndim == 2:
+ mask = mask.unsqueeze(0).unsqueeze(0)
+
+ # Batch single mask or add channel dim
+ if mask.ndim == 3:
+ # Single batched mask, no channel dim or single mask not batched but channel dim
+ if mask.shape[0] == 1:
+ mask = mask.unsqueeze(0)
+
+ # Batched masks no channel dim
+ else:
+ mask = mask.unsqueeze(1)
+
+ assert image.ndim == 4 and mask.ndim == 4, "Image and Mask must have 4 dimensions"
+ assert image.shape[-2:] == mask.shape[-2:], "Image and Mask must have the same spatial dimensions"
+ assert image.shape[0] == mask.shape[0], "Image and Mask must have the same batch size"
+
+ # Check image is in [-1, 1]
+ if image.min() < -1 or image.max() > 1:
+ raise ValueError("Image should be in [-1, 1] range")
+
+ # Check mask is in [0, 1]
+ if mask.min() < 0 or mask.max() > 1:
+ raise ValueError("Mask should be in [0, 1] range")
+
+ # Binarize mask
+ mask[mask < 0.5] = 0
+ mask[mask >= 0.5] = 1
+
+ # Image as float32
+ image = image.to(dtype=torch.float32)
+ elif isinstance(mask, torch.Tensor):
+ raise TypeError(f"`mask` is a torch.Tensor but `image` (type: {type(image)} is not")
+ else:
+ # preprocess image
+ if isinstance(image, (PIL.Image.Image, np.ndarray)):
+ image = [image]
+ if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
+ # resize all images w.r.t passed height an width
+ image = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in image]
+ image = [np.array(i.convert("RGB"))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ elif isinstance(image, list) and isinstance(image[0], np.ndarray):
+ image = np.concatenate([i[None, :] for i in image], axis=0)
+
+ image = image.transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
+
+ # preprocess mask
+ if isinstance(mask, (PIL.Image.Image, np.ndarray)):
+ mask = [mask]
+
+ if isinstance(mask, list) and isinstance(mask[0], PIL.Image.Image):
+ mask = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in mask]
+ mask = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask], axis=0)
+ mask = mask.astype(np.float32) / 255.0
+ elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
+ mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
+
+ mask[mask < 0.5] = 0
+ mask[mask >= 0.5] = 1
+ mask = torch.from_numpy(mask)
+
+ masked_image = image * (mask < 0.5)
+
+ return mask, masked_image
+
+
+class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ In addition the pipeline inherits the following loading methods:
+ - *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
+ Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets
+ as a list, the outputs from each ControlNet are added together to create one combined additional
+ conditioning.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ if isinstance(controlnet, (list, tuple)):
+ controlnet = MultiControlNetModel(controlnet)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ controlnet=controlnet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
+ several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.controlnet]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ # the safety checker can offload the vae again
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # control net hook has be manually offloaded as it alternates with unet
+ cpu_offload_with_hook(self.controlnet, device)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif prompt is not None and type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is None:
+ has_nsfw_concept = None
+ else:
+ if torch.is_tensor(image):
+ feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
+ else:
+ feature_extractor_input = self.image_processor.numpy_to_pil(image)
+ safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ warnings.warn(
+ "The decode_latents method is deprecated and will be removed in a future version. Please"
+ " use VaeImageProcessor instead",
+ FutureWarning,
+ )
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents, return_dict=False)[0]
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ image,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ controlnet_conditioning_scale=1.0,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # `prompt` needs more sophisticated handling when there are multiple
+ # conditionings.
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if isinstance(prompt, list):
+ logger.warning(
+ f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
+ " prompts. The conditionings will be fixed across the prompts."
+ )
+
+ # Check `image`
+ is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
+ self.controlnet, torch._dynamo.eval_frame.OptimizedModule
+ )
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ self.check_image(image, prompt, prompt_embeds)
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if not isinstance(image, list):
+ raise TypeError("For multiple controlnets: `image` must be type `list`")
+
+ # When `image` is a nested list:
+ # (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
+ elif any(isinstance(i, list) for i in image):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif len(image) != len(self.controlnet.nets):
+ raise ValueError(
+ "For multiple controlnets: `image` must have the same length as the number of controlnets."
+ )
+
+ for image_ in image:
+ self.check_image(image_, prompt, prompt_embeds)
+ else:
+ assert False
+
+ # Check `controlnet_conditioning_scale`
+ if (
+ isinstance(self.controlnet, ControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, ControlNetModel)
+ ):
+ if not isinstance(controlnet_conditioning_scale, float):
+ raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
+ elif (
+ isinstance(self.controlnet, MultiControlNetModel)
+ or is_compiled
+ and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
+ ):
+ if isinstance(controlnet_conditioning_scale, list):
+ if any(isinstance(i, list) for i in controlnet_conditioning_scale):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
+ self.controlnet.nets
+ ):
+ raise ValueError(
+ "For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
+ " the same length as the number of controlnets"
+ )
+ else:
+ assert False
+
+ def check_image(self, image, prompt, prompt_embeds):
+ image_is_pil = isinstance(image, PIL.Image.Image)
+ image_is_tensor = isinstance(image, torch.Tensor)
+ image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
+ image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
+
+ if not image_is_pil and not image_is_tensor and not image_is_pil_list and not image_is_tensor_list:
+ raise TypeError(
+ "image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
+ )
+
+ if image_is_pil:
+ image_batch_size = 1
+ elif image_is_tensor:
+ image_batch_size = image.shape[0]
+ elif image_is_pil_list:
+ image_batch_size = len(image)
+ elif image_is_tensor_list:
+ image_batch_size = len(image)
+
+ if prompt is not None and isinstance(prompt, str):
+ prompt_batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ prompt_batch_size = len(prompt)
+ elif prompt_embeds is not None:
+ prompt_batch_size = prompt_embeds.shape[0]
+
+ if image_batch_size != 1 and image_batch_size != prompt_batch_size:
+ raise ValueError(
+ f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
+ )
+
+ # Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.prepare_image
+ def prepare_control_image(
+ self,
+ image,
+ width,
+ height,
+ batch_size,
+ num_images_per_prompt,
+ device,
+ dtype,
+ do_classifier_free_guidance=False,
+ guess_mode=False,
+ ):
+ if not isinstance(image, torch.Tensor):
+ if isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ images = []
+
+ for image_ in image:
+ image_ = image_.convert("RGB")
+ image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
+ image_ = np.array(image_)
+ image_ = image_[None, :]
+ images.append(image_)
+
+ image = images
+
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+
+ image_batch_size = image.shape[0]
+
+ if image_batch_size == 1:
+ repeat_by = batch_size
+ else:
+ # image batch size is the same as prompt batch size
+ repeat_by = num_images_per_prompt
+
+ image = image.repeat_interleave(repeat_by, dim=0)
+
+ image = image.to(device=device, dtype=dtype)
+
+ if do_classifier_free_guidance and not guess_mode:
+ image = torch.cat([image] * 2)
+
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint.StableDiffusionInpaintPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ def _default_height_width(self, height, width, image):
+ # NOTE: It is possible that a list of images have different
+ # dimensions for each image, so just checking the first image
+ # is not _exactly_ correct, but it is simple.
+ while isinstance(image, list):
+ image = image[0]
+
+ if height is None:
+ if isinstance(image, PIL.Image.Image):
+ height = image.height
+ elif isinstance(image, torch.Tensor):
+ height = image.shape[2]
+
+ height = (height // 8) * 8 # round down to nearest multiple of 8
+
+ if width is None:
+ if isinstance(image, PIL.Image.Image):
+ width = image.width
+ elif isinstance(image, torch.Tensor):
+ width = image.shape[3]
+
+ width = (width // 8) * 8 # round down to nearest multiple of 8
+
+ return height, width
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint.StableDiffusionInpaintPipeline.prepare_mask_latents
+ def prepare_mask_latents(
+ self, mask, masked_image, batch_size, height, width, dtype, device, generator, do_classifier_free_guidance
+ ):
+ # resize the mask to latents shape as we concatenate the mask to the latents
+ # we do that before converting to dtype to avoid breaking in case we're using cpu_offload
+ # and half precision
+ mask = torch.nn.functional.interpolate(
+ mask, size=(height // self.vae_scale_factor, width // self.vae_scale_factor)
+ )
+ mask = mask.to(device=device, dtype=dtype)
+
+ masked_image = masked_image.to(device=device, dtype=dtype)
+
+ # encode the mask image into latents space so we can concatenate it to the latents
+ if isinstance(generator, list):
+ masked_image_latents = [
+ self.vae.encode(masked_image[i : i + 1]).latent_dist.sample(generator=generator[i])
+ for i in range(batch_size)
+ ]
+ masked_image_latents = torch.cat(masked_image_latents, dim=0)
+ else:
+ masked_image_latents = self.vae.encode(masked_image).latent_dist.sample(generator=generator)
+ masked_image_latents = self.vae.config.scaling_factor * masked_image_latents
+
+ # duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
+ if mask.shape[0] < batch_size:
+ if not batch_size % mask.shape[0] == 0:
+ raise ValueError(
+ "The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
+ f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
+ " of masks that you pass is divisible by the total requested batch size."
+ )
+ mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
+ if masked_image_latents.shape[0] < batch_size:
+ if not batch_size % masked_image_latents.shape[0] == 0:
+ raise ValueError(
+ "The passed images and the required batch size don't match. Images are supposed to be duplicated"
+ f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
+ " Make sure the number of images that you pass is divisible by the total requested batch size."
+ )
+ masked_image_latents = masked_image_latents.repeat(batch_size // masked_image_latents.shape[0], 1, 1, 1)
+
+ mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
+ masked_image_latents = (
+ torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
+ )
+
+ # aligning device to prevent device errors when concating it with the latent model input
+ masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
+ return mask, masked_image_latents
+
+ # override DiffusionPipeline
+ def save_pretrained(
+ self,
+ save_directory: Union[str, os.PathLike],
+ safe_serialization: bool = False,
+ variant: Optional[str] = None,
+ ):
+ if isinstance(self.controlnet, ControlNetModel):
+ super().save_pretrained(save_directory, safe_serialization, variant)
+ else:
+ raise NotImplementedError("Currently, the `save_pretrained()` is not implemented for Multi-ControlNet.")
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ image: Union[torch.Tensor, PIL.Image.Image] = None,
+ mask_image: Union[torch.Tensor, PIL.Image.Image] = None,
+ control_image: Union[
+ torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]
+ ] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ controlnet_conditioning_scale: Union[float, List[float]] = 0.5,
+ guess_mode: bool = False,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`,
+ `List[List[torch.FloatTensor]]`, or `List[List[PIL.Image.Image]]`):
+ The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
+ the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
+ also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
+ height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
+ specified in init, images must be passed as a list such that each element of the list can be correctly
+ batched for input to a single controlnet.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+ controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 0.5):
+ The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
+ to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
+ corresponding scale as a list. Note that by default, we use a smaller conditioning scale for inpainting
+ than for [`~StableDiffusionControlNetPipeline.__call__`].
+ guess_mode (`bool`, *optional*, defaults to `False`):
+ In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
+ you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height, width = self._default_height_width(height, width, image)
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ control_image,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ prompt_embeds,
+ negative_prompt_embeds,
+ controlnet_conditioning_scale,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
+
+ if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
+ controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
+
+ global_pool_conditions = (
+ controlnet.config.global_pool_conditions
+ if isinstance(controlnet, ControlNetModel)
+ else controlnet.nets[0].config.global_pool_conditions
+ )
+ guess_mode = guess_mode or global_pool_conditions
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare image
+ if isinstance(controlnet, ControlNetModel):
+ control_image = self.prepare_control_image(
+ image=control_image,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+ elif isinstance(controlnet, MultiControlNetModel):
+ control_images = []
+
+ for control_image_ in control_image:
+ control_image_ = self.prepare_control_image(
+ image=control_image_,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ guess_mode=guess_mode,
+ )
+
+ control_images.append(control_image_)
+
+ control_image = control_images
+ else:
+ assert False
+
+ # 4. Preprocess mask and image - resizes image and mask w.r.t height and width
+ # 5. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 6. Prepare latent variables
+ num_channels_latents = self.vae.config.latent_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Prepare mask latent variables
+ mask, masked_image = prepare_mask_and_masked_image(image, mask_image, height, width)
+ mask, masked_image_latents = self.prepare_mask_latents(
+ mask,
+ masked_image,
+ batch_size * num_images_per_prompt,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ do_classifier_free_guidance,
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ if guess_mode and do_classifier_free_guidance:
+ # Infer ControlNet only for the conditional batch.
+ controlnet_latent_model_input = latents
+ controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
+ else:
+ controlnet_latent_model_input = latent_model_input
+ controlnet_prompt_embeds = prompt_embeds
+
+ down_block_res_samples, mid_block_res_sample = self.controlnet(
+ controlnet_latent_model_input,
+ t,
+ encoder_hidden_states=controlnet_prompt_embeds,
+ controlnet_cond=control_image,
+ conditioning_scale=controlnet_conditioning_scale,
+ guess_mode=guess_mode,
+ return_dict=False,
+ )
+
+ if guess_mode and do_classifier_free_guidance:
+ # Infered ControlNet only for the conditional batch.
+ # To apply the output of ControlNet to both the unconditional and conditional batches,
+ # add 0 to the unconditional batch to keep it unchanged.
+ down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
+ mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
+
+ # predict the noise residual
+ latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ down_block_additional_residuals=down_block_res_samples,
+ mid_block_additional_residual=mid_block_res_sample,
+ return_dict=False,
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # If we do sequential model offloading, let's offload unet and controlnet
+ # manually for max memory savings
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.unet.to("cpu")
+ self.controlnet.to("cpu")
+ torch.cuda.empty_cache()
+
+ if not output_type == "latent":
+ image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+ else:
+ image = latents
+ has_nsfw_concept = None
+
+ if has_nsfw_concept is None:
+ do_denormalize = [True] * image.shape[0]
+ else:
+ do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
+
+ image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/src/diffusers/pipelines/controlnet/pipeline_flax_controlnet.py b/src/diffusers/pipelines/controlnet/pipeline_flax_controlnet.py
new file mode 100644
index 000000000000..6003fc96b0ad
--- /dev/null
+++ b/src/diffusers/pipelines/controlnet/pipeline_flax_controlnet.py
@@ -0,0 +1,537 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import warnings
+from functools import partial
+from typing import Dict, List, Optional, Union
+
+import jax
+import jax.numpy as jnp
+import numpy as np
+from flax.core.frozen_dict import FrozenDict
+from flax.jax_utils import unreplicate
+from flax.training.common_utils import shard
+from PIL import Image
+from transformers import CLIPFeatureExtractor, CLIPTokenizer, FlaxCLIPTextModel
+
+from ...models import FlaxAutoencoderKL, FlaxControlNetModel, FlaxUNet2DConditionModel
+from ...schedulers import (
+ FlaxDDIMScheduler,
+ FlaxDPMSolverMultistepScheduler,
+ FlaxLMSDiscreteScheduler,
+ FlaxPNDMScheduler,
+)
+from ...utils import PIL_INTERPOLATION, logging, replace_example_docstring
+from ..pipeline_flax_utils import FlaxDiffusionPipeline
+from ..stable_diffusion import FlaxStableDiffusionPipelineOutput
+from ..stable_diffusion.safety_checker_flax import FlaxStableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+# Set to True to use python for loop instead of jax.fori_loop for easier debugging
+DEBUG = False
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import jax
+ >>> import numpy as np
+ >>> import jax.numpy as jnp
+ >>> from flax.jax_utils import replicate
+ >>> from flax.training.common_utils import shard
+ >>> from diffusers.utils import load_image
+ >>> from PIL import Image
+ >>> from diffusers import FlaxStableDiffusionControlNetPipeline, FlaxControlNetModel
+
+
+ >>> def image_grid(imgs, rows, cols):
+ ... w, h = imgs[0].size
+ ... grid = Image.new("RGB", size=(cols * w, rows * h))
+ ... for i, img in enumerate(imgs):
+ ... grid.paste(img, box=(i % cols * w, i // cols * h))
+ ... return grid
+
+
+ >>> def create_key(seed=0):
+ ... return jax.random.PRNGKey(seed)
+
+
+ >>> rng = create_key(0)
+
+ >>> # get canny image
+ >>> canny_image = load_image(
+ ... "https://huggingface.co/datasets/YiYiXu/test-doc-assets/resolve/main/blog_post_cell_10_output_0.jpeg"
+ ... )
+
+ >>> prompts = "best quality, extremely detailed"
+ >>> negative_prompts = "monochrome, lowres, bad anatomy, worst quality, low quality"
+
+ >>> # load control net and stable diffusion v1-5
+ >>> controlnet, controlnet_params = FlaxControlNetModel.from_pretrained(
+ ... "lllyasviel/sd-controlnet-canny", from_pt=True, dtype=jnp.float32
+ ... )
+ >>> pipe, params = FlaxStableDiffusionControlNetPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, revision="flax", dtype=jnp.float32
+ ... )
+ >>> params["controlnet"] = controlnet_params
+
+ >>> num_samples = jax.device_count()
+ >>> rng = jax.random.split(rng, jax.device_count())
+
+ >>> prompt_ids = pipe.prepare_text_inputs([prompts] * num_samples)
+ >>> negative_prompt_ids = pipe.prepare_text_inputs([negative_prompts] * num_samples)
+ >>> processed_image = pipe.prepare_image_inputs([canny_image] * num_samples)
+
+ >>> p_params = replicate(params)
+ >>> prompt_ids = shard(prompt_ids)
+ >>> negative_prompt_ids = shard(negative_prompt_ids)
+ >>> processed_image = shard(processed_image)
+
+ >>> output = pipe(
+ ... prompt_ids=prompt_ids,
+ ... image=processed_image,
+ ... params=p_params,
+ ... prng_seed=rng,
+ ... num_inference_steps=50,
+ ... neg_prompt_ids=negative_prompt_ids,
+ ... jit=True,
+ ... ).images
+
+ >>> output_images = pipe.numpy_to_pil(np.asarray(output.reshape((num_samples,) + output.shape[-3:])))
+ >>> output_images = image_grid(output_images, num_samples // 4, 4)
+ >>> output_images.save("generated_image.png")
+ ```
+"""
+
+
+class FlaxStableDiffusionControlNetPipeline(FlaxDiffusionPipeline):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion with ControlNet Guidance.
+
+ This model inherits from [`FlaxDiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`FlaxAutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`FlaxCLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.FlaxCLIPTextModel),
+ specifically the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`FlaxUNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ controlnet ([`FlaxControlNetModel`]:
+ Provides additional conditioning to the unet during the denoising process.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`FlaxDDIMScheduler`], [`FlaxLMSDiscreteScheduler`], [`FlaxPNDMScheduler`], or
+ [`FlaxDPMSolverMultistepScheduler`].
+ safety_checker ([`FlaxStableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPFeatureExtractor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+
+ def __init__(
+ self,
+ vae: FlaxAutoencoderKL,
+ text_encoder: FlaxCLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: FlaxUNet2DConditionModel,
+ controlnet: FlaxControlNetModel,
+ scheduler: Union[
+ FlaxDDIMScheduler, FlaxPNDMScheduler, FlaxLMSDiscreteScheduler, FlaxDPMSolverMultistepScheduler
+ ],
+ safety_checker: FlaxStableDiffusionSafetyChecker,
+ feature_extractor: CLIPFeatureExtractor,
+ dtype: jnp.dtype = jnp.float32,
+ ):
+ super().__init__()
+ self.dtype = dtype
+
+ if safety_checker is None:
+ logger.warn(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ controlnet=controlnet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ def prepare_text_inputs(self, prompt: Union[str, List[str]]):
+ if not isinstance(prompt, (str, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ text_input = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+
+ return text_input.input_ids
+
+ def prepare_image_inputs(self, image: Union[Image.Image, List[Image.Image]]):
+ if not isinstance(image, (Image.Image, list)):
+ raise ValueError(f"image has to be of type `PIL.Image.Image` or list but is {type(image)}")
+
+ if isinstance(image, Image.Image):
+ image = [image]
+
+ processed_images = jnp.concatenate([preprocess(img, jnp.float32) for img in image])
+
+ return processed_images
+
+ def _get_has_nsfw_concepts(self, features, params):
+ has_nsfw_concepts = self.safety_checker(features, params)
+ return has_nsfw_concepts
+
+ def _run_safety_checker(self, images, safety_model_params, jit=False):
+ # safety_model_params should already be replicated when jit is True
+ pil_images = [Image.fromarray(image) for image in images]
+ features = self.feature_extractor(pil_images, return_tensors="np").pixel_values
+
+ if jit:
+ features = shard(features)
+ has_nsfw_concepts = _p_get_has_nsfw_concepts(self, features, safety_model_params)
+ has_nsfw_concepts = unshard(has_nsfw_concepts)
+ safety_model_params = unreplicate(safety_model_params)
+ else:
+ has_nsfw_concepts = self._get_has_nsfw_concepts(features, safety_model_params)
+
+ images_was_copied = False
+ for idx, has_nsfw_concept in enumerate(has_nsfw_concepts):
+ if has_nsfw_concept:
+ if not images_was_copied:
+ images_was_copied = True
+ images = images.copy()
+
+ images[idx] = np.zeros(images[idx].shape, dtype=np.uint8) # black image
+
+ if any(has_nsfw_concepts):
+ warnings.warn(
+ "Potential NSFW content was detected in one or more images. A black image will be returned"
+ " instead. Try again with a different prompt and/or seed."
+ )
+
+ return images, has_nsfw_concepts
+
+ def _generate(
+ self,
+ prompt_ids: jnp.array,
+ image: jnp.array,
+ params: Union[Dict, FrozenDict],
+ prng_seed: jax.random.KeyArray,
+ num_inference_steps: int,
+ guidance_scale: float,
+ latents: Optional[jnp.array] = None,
+ neg_prompt_ids: Optional[jnp.array] = None,
+ controlnet_conditioning_scale: float = 1.0,
+ ):
+ height, width = image.shape[-2:]
+ if height % 64 != 0 or width % 64 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 64 but are {height} and {width}.")
+
+ # get prompt text embeddings
+ prompt_embeds = self.text_encoder(prompt_ids, params=params["text_encoder"])[0]
+
+ # TODO: currently it is assumed `do_classifier_free_guidance = guidance_scale > 1.0`
+ # implement this conditional `do_classifier_free_guidance = guidance_scale > 1.0`
+ batch_size = prompt_ids.shape[0]
+
+ max_length = prompt_ids.shape[-1]
+
+ if neg_prompt_ids is None:
+ uncond_input = self.tokenizer(
+ [""] * batch_size, padding="max_length", max_length=max_length, return_tensors="np"
+ ).input_ids
+ else:
+ uncond_input = neg_prompt_ids
+ negative_prompt_embeds = self.text_encoder(uncond_input, params=params["text_encoder"])[0]
+ context = jnp.concatenate([negative_prompt_embeds, prompt_embeds])
+
+ image = jnp.concatenate([image] * 2)
+
+ latents_shape = (
+ batch_size,
+ self.unet.config.in_channels,
+ height // self.vae_scale_factor,
+ width // self.vae_scale_factor,
+ )
+ if latents is None:
+ latents = jax.random.normal(prng_seed, shape=latents_shape, dtype=jnp.float32)
+ else:
+ if latents.shape != latents_shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
+
+ def loop_body(step, args):
+ latents, scheduler_state = args
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ latents_input = jnp.concatenate([latents] * 2)
+
+ t = jnp.array(scheduler_state.timesteps, dtype=jnp.int32)[step]
+ timestep = jnp.broadcast_to(t, latents_input.shape[0])
+
+ latents_input = self.scheduler.scale_model_input(scheduler_state, latents_input, t)
+
+ down_block_res_samples, mid_block_res_sample = self.controlnet.apply(
+ {"params": params["controlnet"]},
+ jnp.array(latents_input),
+ jnp.array(timestep, dtype=jnp.int32),
+ encoder_hidden_states=context,
+ controlnet_cond=image,
+ conditioning_scale=controlnet_conditioning_scale,
+ return_dict=False,
+ )
+
+ # predict the noise residual
+ noise_pred = self.unet.apply(
+ {"params": params["unet"]},
+ jnp.array(latents_input),
+ jnp.array(timestep, dtype=jnp.int32),
+ encoder_hidden_states=context,
+ down_block_additional_residuals=down_block_res_samples,
+ mid_block_additional_residual=mid_block_res_sample,
+ ).sample
+
+ # perform guidance
+ noise_pred_uncond, noise_prediction_text = jnp.split(noise_pred, 2, axis=0)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents, scheduler_state = self.scheduler.step(scheduler_state, noise_pred, t, latents).to_tuple()
+ return latents, scheduler_state
+
+ scheduler_state = self.scheduler.set_timesteps(
+ params["scheduler"], num_inference_steps=num_inference_steps, shape=latents_shape
+ )
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * params["scheduler"].init_noise_sigma
+
+ if DEBUG:
+ # run with python for loop
+ for i in range(num_inference_steps):
+ latents, scheduler_state = loop_body(i, (latents, scheduler_state))
+ else:
+ latents, _ = jax.lax.fori_loop(0, num_inference_steps, loop_body, (latents, scheduler_state))
+
+ # scale and decode the image latents with vae
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.apply({"params": params["vae"]}, latents, method=self.vae.decode).sample
+
+ image = (image / 2 + 0.5).clip(0, 1).transpose(0, 2, 3, 1)
+ return image
+
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt_ids: jnp.array,
+ image: jnp.array,
+ params: Union[Dict, FrozenDict],
+ prng_seed: jax.random.KeyArray,
+ num_inference_steps: int = 50,
+ guidance_scale: Union[float, jnp.array] = 7.5,
+ latents: jnp.array = None,
+ neg_prompt_ids: jnp.array = None,
+ controlnet_conditioning_scale: Union[float, jnp.array] = 1.0,
+ return_dict: bool = True,
+ jit: bool = False,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt_ids (`jnp.array`):
+ The prompt or prompts to guide the image generation.
+ image (`jnp.array`):
+ Array representing the ControlNet input condition. ControlNet use this input condition to generate
+ guidance to Unet.
+ params (`Dict` or `FrozenDict`): Dictionary containing the model parameters/weights
+ prng_seed (`jax.random.KeyArray` or `jax.Array`): Array containing random number generator key
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ latents (`jnp.array`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ controlnet_conditioning_scale (`float` or `jnp.array`, *optional*, defaults to 1.0):
+ The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
+ to the residual in the original unet.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] instead of
+ a plain tuple.
+ jit (`bool`, defaults to `False`):
+ Whether to run `pmap` versions of the generation and safety scoring functions. NOTE: This argument
+ exists because `__call__` is not yet end-to-end pmap-able. It will be removed in a future release.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a
+ `tuple. When returning a tuple, the first element is a list with the generated images, and the second
+ element is a list of `bool`s denoting whether the corresponding generated image likely represents
+ "not-safe-for-work" (nsfw) content, according to the `safety_checker`.
+ """
+
+ height, width = image.shape[-2:]
+
+ if isinstance(guidance_scale, float):
+ # Convert to a tensor so each device gets a copy. Follow the prompt_ids for
+ # shape information, as they may be sharded (when `jit` is `True`), or not.
+ guidance_scale = jnp.array([guidance_scale] * prompt_ids.shape[0])
+ if len(prompt_ids.shape) > 2:
+ # Assume sharded
+ guidance_scale = guidance_scale[:, None]
+
+ if isinstance(controlnet_conditioning_scale, float):
+ # Convert to a tensor so each device gets a copy. Follow the prompt_ids for
+ # shape information, as they may be sharded (when `jit` is `True`), or not.
+ controlnet_conditioning_scale = jnp.array([controlnet_conditioning_scale] * prompt_ids.shape[0])
+ if len(prompt_ids.shape) > 2:
+ # Assume sharded
+ controlnet_conditioning_scale = controlnet_conditioning_scale[:, None]
+
+ if jit:
+ images = _p_generate(
+ self,
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ controlnet_conditioning_scale,
+ )
+ else:
+ images = self._generate(
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ controlnet_conditioning_scale,
+ )
+
+ if self.safety_checker is not None:
+ safety_params = params["safety_checker"]
+ images_uint8_casted = (images * 255).round().astype("uint8")
+ num_devices, batch_size = images.shape[:2]
+
+ images_uint8_casted = np.asarray(images_uint8_casted).reshape(num_devices * batch_size, height, width, 3)
+ images_uint8_casted, has_nsfw_concept = self._run_safety_checker(images_uint8_casted, safety_params, jit)
+ images = np.asarray(images)
+
+ # block images
+ if any(has_nsfw_concept):
+ for i, is_nsfw in enumerate(has_nsfw_concept):
+ if is_nsfw:
+ images[i] = np.asarray(images_uint8_casted[i])
+
+ images = images.reshape(num_devices, batch_size, height, width, 3)
+ else:
+ images = np.asarray(images)
+ has_nsfw_concept = False
+
+ if not return_dict:
+ return (images, has_nsfw_concept)
+
+ return FlaxStableDiffusionPipelineOutput(images=images, nsfw_content_detected=has_nsfw_concept)
+
+
+# Static argnums are pipe, num_inference_steps. A change would trigger recompilation.
+# Non-static args are (sharded) input tensors mapped over their first dimension (hence, `0`).
+@partial(
+ jax.pmap,
+ in_axes=(None, 0, 0, 0, 0, None, 0, 0, 0, 0),
+ static_broadcasted_argnums=(0, 5),
+)
+def _p_generate(
+ pipe,
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ controlnet_conditioning_scale,
+):
+ return pipe._generate(
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ controlnet_conditioning_scale,
+ )
+
+
+@partial(jax.pmap, static_broadcasted_argnums=(0,))
+def _p_get_has_nsfw_concepts(pipe, features, params):
+ return pipe._get_has_nsfw_concepts(features, params)
+
+
+def unshard(x: jnp.ndarray):
+ # einops.rearrange(x, 'd b ... -> (d b) ...')
+ num_devices, batch_size = x.shape[:2]
+ rest = x.shape[2:]
+ return x.reshape(num_devices * batch_size, *rest)
+
+
+def preprocess(image, dtype):
+ image = image.convert("RGB")
+ w, h = image.size
+ w, h = (x - x % 64 for x in (w, h)) # resize to integer multiple of 64
+ image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
+ image = jnp.array(image).astype(dtype) / 255.0
+ image = image[None].transpose(0, 3, 1, 2)
+ return image
diff --git a/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py b/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py
index e3fe20e196d8..911a5018de18 100644
--- a/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py
+++ b/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py
@@ -8,10 +8,10 @@
from ...image_processor import VaeImageProcessor
from ...models import AutoencoderKL, UNet2DConditionModel
-from ...pipeline_utils import DiffusionPipeline
from ...pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from ...schedulers import KarrasDiffusionSchedulers
from ...utils import logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline
from . import SemanticStableDiffusionPipelineOutput
diff --git a/src/diffusers/pipelines/stable_diffusion/__init__.py b/src/diffusers/pipelines/stable_diffusion/__init__.py
index b89dde319cb3..f39ae67a9aff 100644
--- a/src/diffusers/pipelines/stable_diffusion/__init__.py
+++ b/src/diffusers/pipelines/stable_diffusion/__init__.py
@@ -45,7 +45,6 @@ class StableDiffusionPipelineOutput(BaseOutput):
from .pipeline_cycle_diffusion import CycleDiffusionPipeline
from .pipeline_stable_diffusion import StableDiffusionPipeline
from .pipeline_stable_diffusion_attend_and_excite import StableDiffusionAttendAndExcitePipeline
- from .pipeline_stable_diffusion_controlnet import StableDiffusionControlNetPipeline
from .pipeline_stable_diffusion_img2img import StableDiffusionImg2ImgPipeline
from .pipeline_stable_diffusion_inpaint import StableDiffusionInpaintPipeline
from .pipeline_stable_diffusion_inpaint_legacy import StableDiffusionInpaintPipelineLegacy
@@ -130,7 +129,6 @@ class FlaxStableDiffusionPipelineOutput(BaseOutput):
from ...schedulers.scheduling_pndm_flax import PNDMSchedulerState
from .pipeline_flax_stable_diffusion import FlaxStableDiffusionPipeline
- from .pipeline_flax_stable_diffusion_controlnet import FlaxStableDiffusionControlNetPipeline
from .pipeline_flax_stable_diffusion_img2img import FlaxStableDiffusionImg2ImgPipeline
from .pipeline_flax_stable_diffusion_inpaint import FlaxStableDiffusionInpaintPipeline
from .safety_checker_flax import FlaxStableDiffusionSafetyChecker
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_controlnet.py b/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_controlnet.py
index 7035242a0cda..bec2424ece4d 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_controlnet.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_controlnet.py
@@ -12,526 +12,17 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import warnings
-from functools import partial
-from typing import Dict, List, Optional, Union
+# NOTE: This file is deprecated and will be removed in a future version.
+# It only exists so that temporarely `from diffusers.pipelines import DiffusionPipeline` works
-import jax
-import jax.numpy as jnp
-import numpy as np
-from flax.core.frozen_dict import FrozenDict
-from flax.jax_utils import unreplicate
-from flax.training.common_utils import shard
-from PIL import Image
-from transformers import CLIPFeatureExtractor, CLIPTokenizer, FlaxCLIPTextModel
+from ...utils import deprecate
+from ..controlnet.pipeline_flax_controlnet import FlaxStableDiffusionControlNetPipeline # noqa: F401
-from ...models import FlaxAutoencoderKL, FlaxControlNetModel, FlaxUNet2DConditionModel
-from ...schedulers import (
- FlaxDDIMScheduler,
- FlaxDPMSolverMultistepScheduler,
- FlaxLMSDiscreteScheduler,
- FlaxPNDMScheduler,
-)
-from ...utils import PIL_INTERPOLATION, logging, replace_example_docstring
-from ..pipeline_flax_utils import FlaxDiffusionPipeline
-from . import FlaxStableDiffusionPipelineOutput
-from .safety_checker_flax import FlaxStableDiffusionSafetyChecker
-
-
-logger = logging.get_logger(__name__) # pylint: disable=invalid-name
-
-# Set to True to use python for loop instead of jax.fori_loop for easier debugging
-DEBUG = False
-
-EXAMPLE_DOC_STRING = """
- Examples:
- ```py
- >>> import jax
- >>> import numpy as np
- >>> import jax.numpy as jnp
- >>> from flax.jax_utils import replicate
- >>> from flax.training.common_utils import shard
- >>> from diffusers.utils import load_image
- >>> from PIL import Image
- >>> from diffusers import FlaxStableDiffusionControlNetPipeline, FlaxControlNetModel
-
-
- >>> def image_grid(imgs, rows, cols):
- ... w, h = imgs[0].size
- ... grid = Image.new("RGB", size=(cols * w, rows * h))
- ... for i, img in enumerate(imgs):
- ... grid.paste(img, box=(i % cols * w, i // cols * h))
- ... return grid
-
-
- >>> def create_key(seed=0):
- ... return jax.random.PRNGKey(seed)
-
-
- >>> rng = create_key(0)
-
- >>> # get canny image
- >>> canny_image = load_image(
- ... "https://huggingface.co/datasets/YiYiXu/test-doc-assets/resolve/main/blog_post_cell_10_output_0.jpeg"
- ... )
-
- >>> prompts = "best quality, extremely detailed"
- >>> negative_prompts = "monochrome, lowres, bad anatomy, worst quality, low quality"
-
- >>> # load control net and stable diffusion v1-5
- >>> controlnet, controlnet_params = FlaxControlNetModel.from_pretrained(
- ... "lllyasviel/sd-controlnet-canny", from_pt=True, dtype=jnp.float32
- ... )
- >>> pipe, params = FlaxStableDiffusionControlNetPipeline.from_pretrained(
- ... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, revision="flax", dtype=jnp.float32
- ... )
- >>> params["controlnet"] = controlnet_params
-
- >>> num_samples = jax.device_count()
- >>> rng = jax.random.split(rng, jax.device_count())
-
- >>> prompt_ids = pipe.prepare_text_inputs([prompts] * num_samples)
- >>> negative_prompt_ids = pipe.prepare_text_inputs([negative_prompts] * num_samples)
- >>> processed_image = pipe.prepare_image_inputs([canny_image] * num_samples)
-
- >>> p_params = replicate(params)
- >>> prompt_ids = shard(prompt_ids)
- >>> negative_prompt_ids = shard(negative_prompt_ids)
- >>> processed_image = shard(processed_image)
-
- >>> output = pipe(
- ... prompt_ids=prompt_ids,
- ... image=processed_image,
- ... params=p_params,
- ... prng_seed=rng,
- ... num_inference_steps=50,
- ... neg_prompt_ids=negative_prompt_ids,
- ... jit=True,
- ... ).images
-
- >>> output_images = pipe.numpy_to_pil(np.asarray(output.reshape((num_samples,) + output.shape[-3:])))
- >>> output_images = image_grid(output_images, num_samples // 4, 4)
- >>> output_images.save("generated_image.png")
- ```
-"""
-
-
-class FlaxStableDiffusionControlNetPipeline(FlaxDiffusionPipeline):
- r"""
- Pipeline for text-to-image generation using Stable Diffusion with ControlNet Guidance.
-
- This model inherits from [`FlaxDiffusionPipeline`]. Check the superclass documentation for the generic methods the
- library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
-
- Args:
- vae ([`FlaxAutoencoderKL`]):
- Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
- text_encoder ([`FlaxCLIPTextModel`]):
- Frozen text-encoder. Stable Diffusion uses the text portion of
- [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.FlaxCLIPTextModel),
- specifically the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
- tokenizer (`CLIPTokenizer`):
- Tokenizer of class
- [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
- unet ([`FlaxUNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
- controlnet ([`FlaxControlNetModel`]:
- Provides additional conditioning to the unet during the denoising process.
- scheduler ([`SchedulerMixin`]):
- A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
- [`FlaxDDIMScheduler`], [`FlaxLMSDiscreteScheduler`], [`FlaxPNDMScheduler`], or
- [`FlaxDPMSolverMultistepScheduler`].
- safety_checker ([`FlaxStableDiffusionSafetyChecker`]):
- Classification module that estimates whether generated images could be considered offensive or harmful.
- Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
- feature_extractor ([`CLIPFeatureExtractor`]):
- Model that extracts features from generated images to be used as inputs for the `safety_checker`.
- """
-
- def __init__(
- self,
- vae: FlaxAutoencoderKL,
- text_encoder: FlaxCLIPTextModel,
- tokenizer: CLIPTokenizer,
- unet: FlaxUNet2DConditionModel,
- controlnet: FlaxControlNetModel,
- scheduler: Union[
- FlaxDDIMScheduler, FlaxPNDMScheduler, FlaxLMSDiscreteScheduler, FlaxDPMSolverMultistepScheduler
- ],
- safety_checker: FlaxStableDiffusionSafetyChecker,
- feature_extractor: CLIPFeatureExtractor,
- dtype: jnp.dtype = jnp.float32,
- ):
- super().__init__()
- self.dtype = dtype
-
- if safety_checker is None:
- logger.warn(
- f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
- " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
- " results in services or applications open to the public. Both the diffusers team and Hugging Face"
- " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
- " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
- " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
- )
-
- self.register_modules(
- vae=vae,
- text_encoder=text_encoder,
- tokenizer=tokenizer,
- unet=unet,
- controlnet=controlnet,
- scheduler=scheduler,
- safety_checker=safety_checker,
- feature_extractor=feature_extractor,
- )
- self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
-
- def prepare_text_inputs(self, prompt: Union[str, List[str]]):
- if not isinstance(prompt, (str, list)):
- raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
-
- text_input = self.tokenizer(
- prompt,
- padding="max_length",
- max_length=self.tokenizer.model_max_length,
- truncation=True,
- return_tensors="np",
- )
-
- return text_input.input_ids
-
- def prepare_image_inputs(self, image: Union[Image.Image, List[Image.Image]]):
- if not isinstance(image, (Image.Image, list)):
- raise ValueError(f"image has to be of type `PIL.Image.Image` or list but is {type(image)}")
-
- if isinstance(image, Image.Image):
- image = [image]
-
- processed_images = jnp.concatenate([preprocess(img, jnp.float32) for img in image])
-
- return processed_images
-
- def _get_has_nsfw_concepts(self, features, params):
- has_nsfw_concepts = self.safety_checker(features, params)
- return has_nsfw_concepts
-
- def _run_safety_checker(self, images, safety_model_params, jit=False):
- # safety_model_params should already be replicated when jit is True
- pil_images = [Image.fromarray(image) for image in images]
- features = self.feature_extractor(pil_images, return_tensors="np").pixel_values
-
- if jit:
- features = shard(features)
- has_nsfw_concepts = _p_get_has_nsfw_concepts(self, features, safety_model_params)
- has_nsfw_concepts = unshard(has_nsfw_concepts)
- safety_model_params = unreplicate(safety_model_params)
- else:
- has_nsfw_concepts = self._get_has_nsfw_concepts(features, safety_model_params)
-
- images_was_copied = False
- for idx, has_nsfw_concept in enumerate(has_nsfw_concepts):
- if has_nsfw_concept:
- if not images_was_copied:
- images_was_copied = True
- images = images.copy()
-
- images[idx] = np.zeros(images[idx].shape, dtype=np.uint8) # black image
-
- if any(has_nsfw_concepts):
- warnings.warn(
- "Potential NSFW content was detected in one or more images. A black image will be returned"
- " instead. Try again with a different prompt and/or seed."
- )
-
- return images, has_nsfw_concepts
- def _generate(
- self,
- prompt_ids: jnp.array,
- image: jnp.array,
- params: Union[Dict, FrozenDict],
- prng_seed: jax.random.KeyArray,
- num_inference_steps: int,
- guidance_scale: float,
- latents: Optional[jnp.array] = None,
- neg_prompt_ids: Optional[jnp.array] = None,
- controlnet_conditioning_scale: float = 1.0,
- ):
- height, width = image.shape[-2:]
- if height % 64 != 0 or width % 64 != 0:
- raise ValueError(f"`height` and `width` have to be divisible by 64 but are {height} and {width}.")
-
- # get prompt text embeddings
- prompt_embeds = self.text_encoder(prompt_ids, params=params["text_encoder"])[0]
-
- # TODO: currently it is assumed `do_classifier_free_guidance = guidance_scale > 1.0`
- # implement this conditional `do_classifier_free_guidance = guidance_scale > 1.0`
- batch_size = prompt_ids.shape[0]
-
- max_length = prompt_ids.shape[-1]
-
- if neg_prompt_ids is None:
- uncond_input = self.tokenizer(
- [""] * batch_size, padding="max_length", max_length=max_length, return_tensors="np"
- ).input_ids
- else:
- uncond_input = neg_prompt_ids
- negative_prompt_embeds = self.text_encoder(uncond_input, params=params["text_encoder"])[0]
- context = jnp.concatenate([negative_prompt_embeds, prompt_embeds])
-
- image = jnp.concatenate([image] * 2)
-
- latents_shape = (
- batch_size,
- self.unet.config.in_channels,
- height // self.vae_scale_factor,
- width // self.vae_scale_factor,
- )
- if latents is None:
- latents = jax.random.normal(prng_seed, shape=latents_shape, dtype=jnp.float32)
- else:
- if latents.shape != latents_shape:
- raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
-
- def loop_body(step, args):
- latents, scheduler_state = args
- # For classifier free guidance, we need to do two forward passes.
- # Here we concatenate the unconditional and text embeddings into a single batch
- # to avoid doing two forward passes
- latents_input = jnp.concatenate([latents] * 2)
-
- t = jnp.array(scheduler_state.timesteps, dtype=jnp.int32)[step]
- timestep = jnp.broadcast_to(t, latents_input.shape[0])
-
- latents_input = self.scheduler.scale_model_input(scheduler_state, latents_input, t)
-
- down_block_res_samples, mid_block_res_sample = self.controlnet.apply(
- {"params": params["controlnet"]},
- jnp.array(latents_input),
- jnp.array(timestep, dtype=jnp.int32),
- encoder_hidden_states=context,
- controlnet_cond=image,
- conditioning_scale=controlnet_conditioning_scale,
- return_dict=False,
- )
-
- # predict the noise residual
- noise_pred = self.unet.apply(
- {"params": params["unet"]},
- jnp.array(latents_input),
- jnp.array(timestep, dtype=jnp.int32),
- encoder_hidden_states=context,
- down_block_additional_residuals=down_block_res_samples,
- mid_block_additional_residual=mid_block_res_sample,
- ).sample
-
- # perform guidance
- noise_pred_uncond, noise_prediction_text = jnp.split(noise_pred, 2, axis=0)
- noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)
-
- # compute the previous noisy sample x_t -> x_t-1
- latents, scheduler_state = self.scheduler.step(scheduler_state, noise_pred, t, latents).to_tuple()
- return latents, scheduler_state
-
- scheduler_state = self.scheduler.set_timesteps(
- params["scheduler"], num_inference_steps=num_inference_steps, shape=latents_shape
- )
-
- # scale the initial noise by the standard deviation required by the scheduler
- latents = latents * params["scheduler"].init_noise_sigma
-
- if DEBUG:
- # run with python for loop
- for i in range(num_inference_steps):
- latents, scheduler_state = loop_body(i, (latents, scheduler_state))
- else:
- latents, _ = jax.lax.fori_loop(0, num_inference_steps, loop_body, (latents, scheduler_state))
-
- # scale and decode the image latents with vae
- latents = 1 / self.vae.config.scaling_factor * latents
- image = self.vae.apply({"params": params["vae"]}, latents, method=self.vae.decode).sample
-
- image = (image / 2 + 0.5).clip(0, 1).transpose(0, 2, 3, 1)
- return image
-
- @replace_example_docstring(EXAMPLE_DOC_STRING)
- def __call__(
- self,
- prompt_ids: jnp.array,
- image: jnp.array,
- params: Union[Dict, FrozenDict],
- prng_seed: jax.random.KeyArray,
- num_inference_steps: int = 50,
- guidance_scale: Union[float, jnp.array] = 7.5,
- latents: jnp.array = None,
- neg_prompt_ids: jnp.array = None,
- controlnet_conditioning_scale: Union[float, jnp.array] = 1.0,
- return_dict: bool = True,
- jit: bool = False,
- ):
- r"""
- Function invoked when calling the pipeline for generation.
-
- Args:
- prompt_ids (`jnp.array`):
- The prompt or prompts to guide the image generation.
- image (`jnp.array`):
- Array representing the ControlNet input condition. ControlNet use this input condition to generate
- guidance to Unet.
- params (`Dict` or `FrozenDict`): Dictionary containing the model parameters/weights
- prng_seed (`jax.random.KeyArray` or `jax.Array`): Array containing random number generator key
- num_inference_steps (`int`, *optional*, defaults to 50):
- The number of denoising steps. More denoising steps usually lead to a higher quality image at the
- expense of slower inference.
- guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
- latents (`jnp.array`, *optional*):
- Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
- generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
- tensor will ge generated by sampling using the supplied random `generator`.
- controlnet_conditioning_scale (`float` or `jnp.array`, *optional*, defaults to 1.0):
- The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
- to the residual in the original unet.
- return_dict (`bool`, *optional*, defaults to `True`):
- Whether or not to return a [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] instead of
- a plain tuple.
- jit (`bool`, defaults to `False`):
- Whether to run `pmap` versions of the generation and safety scoring functions. NOTE: This argument
- exists because `__call__` is not yet end-to-end pmap-able. It will be removed in a future release.
-
- Examples:
-
- Returns:
- [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] or `tuple`:
- [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a
- `tuple. When returning a tuple, the first element is a list with the generated images, and the second
- element is a list of `bool`s denoting whether the corresponding generated image likely represents
- "not-safe-for-work" (nsfw) content, according to the `safety_checker`.
- """
-
- height, width = image.shape[-2:]
-
- if isinstance(guidance_scale, float):
- # Convert to a tensor so each device gets a copy. Follow the prompt_ids for
- # shape information, as they may be sharded (when `jit` is `True`), or not.
- guidance_scale = jnp.array([guidance_scale] * prompt_ids.shape[0])
- if len(prompt_ids.shape) > 2:
- # Assume sharded
- guidance_scale = guidance_scale[:, None]
-
- if isinstance(controlnet_conditioning_scale, float):
- # Convert to a tensor so each device gets a copy. Follow the prompt_ids for
- # shape information, as they may be sharded (when `jit` is `True`), or not.
- controlnet_conditioning_scale = jnp.array([controlnet_conditioning_scale] * prompt_ids.shape[0])
- if len(prompt_ids.shape) > 2:
- # Assume sharded
- controlnet_conditioning_scale = controlnet_conditioning_scale[:, None]
-
- if jit:
- images = _p_generate(
- self,
- prompt_ids,
- image,
- params,
- prng_seed,
- num_inference_steps,
- guidance_scale,
- latents,
- neg_prompt_ids,
- controlnet_conditioning_scale,
- )
- else:
- images = self._generate(
- prompt_ids,
- image,
- params,
- prng_seed,
- num_inference_steps,
- guidance_scale,
- latents,
- neg_prompt_ids,
- controlnet_conditioning_scale,
- )
-
- if self.safety_checker is not None:
- safety_params = params["safety_checker"]
- images_uint8_casted = (images * 255).round().astype("uint8")
- num_devices, batch_size = images.shape[:2]
-
- images_uint8_casted = np.asarray(images_uint8_casted).reshape(num_devices * batch_size, height, width, 3)
- images_uint8_casted, has_nsfw_concept = self._run_safety_checker(images_uint8_casted, safety_params, jit)
- images = np.asarray(images)
-
- # block images
- if any(has_nsfw_concept):
- for i, is_nsfw in enumerate(has_nsfw_concept):
- if is_nsfw:
- images[i] = np.asarray(images_uint8_casted[i])
-
- images = images.reshape(num_devices, batch_size, height, width, 3)
- else:
- images = np.asarray(images)
- has_nsfw_concept = False
-
- if not return_dict:
- return (images, has_nsfw_concept)
-
- return FlaxStableDiffusionPipelineOutput(images=images, nsfw_content_detected=has_nsfw_concept)
-
-
-# Static argnums are pipe, num_inference_steps. A change would trigger recompilation.
-# Non-static args are (sharded) input tensors mapped over their first dimension (hence, `0`).
-@partial(
- jax.pmap,
- in_axes=(None, 0, 0, 0, 0, None, 0, 0, 0, 0),
- static_broadcasted_argnums=(0, 5),
+deprecate(
+ "stable diffusion controlnet",
+ "0.22.0",
+ "Importing `FlaxStableDiffusionControlNetPipeline` from diffusers.pipelines.stable_diffusion.flax_pipeline_stable_diffusion_controlnet is deprecated. Please import `from diffusers import FlaxStableDiffusionControlNetPipeline` instead.",
+ standard_warn=False,
+ stacklevel=3,
)
-def _p_generate(
- pipe,
- prompt_ids,
- image,
- params,
- prng_seed,
- num_inference_steps,
- guidance_scale,
- latents,
- neg_prompt_ids,
- controlnet_conditioning_scale,
-):
- return pipe._generate(
- prompt_ids,
- image,
- params,
- prng_seed,
- num_inference_steps,
- guidance_scale,
- latents,
- neg_prompt_ids,
- controlnet_conditioning_scale,
- )
-
-
-@partial(jax.pmap, static_broadcasted_argnums=(0,))
-def _p_get_has_nsfw_concepts(pipe, features, params):
- return pipe._get_has_nsfw_concepts(features, params)
-
-
-def unshard(x: jnp.ndarray):
- # einops.rearrange(x, 'd b ... -> (d b) ...')
- num_devices, batch_size = x.shape[:2]
- rest = x.shape[2:]
- return x.reshape(num_devices * batch_size, *rest)
-
-
-def preprocess(image, dtype):
- image = image.convert("RGB")
- w, h = image.size
- w, h = (x - x % 64 for x in (w, h)) # resize to integer multiple of 64
- image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
- image = jnp.array(image).astype(dtype) / 255.0
- image = image[None].transpose(0, 3, 1, 2)
- return image
diff --git a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py
index 1cef221ea6e1..c7555e2ebad4 100644
--- a/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py
+++ b/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py
@@ -12,1093 +12,17 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-
-import inspect
-import os
-import warnings
-from typing import Any, Callable, Dict, List, Optional, Tuple, Union
-
-import numpy as np
-import PIL.Image
-import torch
-import torch.nn.functional as F
-from torch import nn
-from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
-
-from ...image_processor import VaeImageProcessor
-from ...loaders import TextualInversionLoaderMixin
-from ...models import AutoencoderKL, ControlNetModel, UNet2DConditionModel
-from ...models.controlnet import ControlNetOutput
-from ...models.modeling_utils import ModelMixin
-from ...schedulers import KarrasDiffusionSchedulers
-from ...utils import (
- PIL_INTERPOLATION,
- is_accelerate_available,
- is_accelerate_version,
- logging,
- randn_tensor,
- replace_example_docstring,
+# NOTE: This file is deprecated and will be removed in a future version.
+# It only exists so that temporarely `from diffusers.pipelines import DiffusionPipeline` works
+from ...utils import deprecate
+from ..controlnet.multicontrolnet import MultiControlNetModel # noqa: F401
+from ..controlnet.pipeline_controlnet import StableDiffusionControlNetPipeline # noqa: F401
+
+
+deprecate(
+ "stable diffusion controlnet",
+ "0.22.0",
+ "Importing `StableDiffusionControlNetPipeline` or `MultiControlNetModel` from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_controlnet is deprecated. Please import `from diffusers import StableDiffusionControlNetPipeline` instead.",
+ standard_warn=False,
+ stacklevel=3,
)
-from ..pipeline_utils import DiffusionPipeline
-from . import StableDiffusionPipelineOutput
-from .safety_checker import StableDiffusionSafetyChecker
-
-
-logger = logging.get_logger(__name__) # pylint: disable=invalid-name
-
-
-EXAMPLE_DOC_STRING = """
- Examples:
- ```py
- >>> # !pip install opencv-python transformers accelerate
- >>> from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
- >>> from diffusers.utils import load_image
- >>> import numpy as np
- >>> import torch
-
- >>> import cv2
- >>> from PIL import Image
-
- >>> # download an image
- >>> image = load_image(
- ... "https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
- ... )
- >>> image = np.array(image)
-
- >>> # get canny image
- >>> image = cv2.Canny(image, 100, 200)
- >>> image = image[:, :, None]
- >>> image = np.concatenate([image, image, image], axis=2)
- >>> canny_image = Image.fromarray(image)
-
- >>> # load control net and stable diffusion v1-5
- >>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
- >>> pipe = StableDiffusionControlNetPipeline.from_pretrained(
- ... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
- ... )
-
- >>> # speed up diffusion process with faster scheduler and memory optimization
- >>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
- >>> # remove following line if xformers is not installed
- >>> pipe.enable_xformers_memory_efficient_attention()
-
- >>> pipe.enable_model_cpu_offload()
-
- >>> # generate image
- >>> generator = torch.manual_seed(0)
- >>> image = pipe(
- ... "futuristic-looking woman", num_inference_steps=20, generator=generator, image=canny_image
- ... ).images[0]
- ```
-"""
-
-
-class MultiControlNetModel(ModelMixin):
- r"""
- Multiple `ControlNetModel` wrapper class for Multi-ControlNet
-
- This module is a wrapper for multiple instances of the `ControlNetModel`. The `forward()` API is designed to be
- compatible with `ControlNetModel`.
-
- Args:
- controlnets (`List[ControlNetModel]`):
- Provides additional conditioning to the unet during the denoising process. You must set multiple
- `ControlNetModel` as a list.
- """
-
- def __init__(self, controlnets: Union[List[ControlNetModel], Tuple[ControlNetModel]]):
- super().__init__()
- self.nets = nn.ModuleList(controlnets)
-
- def forward(
- self,
- sample: torch.FloatTensor,
- timestep: Union[torch.Tensor, float, int],
- encoder_hidden_states: torch.Tensor,
- controlnet_cond: List[torch.tensor],
- conditioning_scale: List[float],
- class_labels: Optional[torch.Tensor] = None,
- timestep_cond: Optional[torch.Tensor] = None,
- attention_mask: Optional[torch.Tensor] = None,
- cross_attention_kwargs: Optional[Dict[str, Any]] = None,
- guess_mode: bool = False,
- return_dict: bool = True,
- ) -> Union[ControlNetOutput, Tuple]:
- for i, (image, scale, controlnet) in enumerate(zip(controlnet_cond, conditioning_scale, self.nets)):
- down_samples, mid_sample = controlnet(
- sample,
- timestep,
- encoder_hidden_states,
- image,
- scale,
- class_labels,
- timestep_cond,
- attention_mask,
- cross_attention_kwargs,
- guess_mode,
- return_dict,
- )
-
- # merge samples
- if i == 0:
- down_block_res_samples, mid_block_res_sample = down_samples, mid_sample
- else:
- down_block_res_samples = [
- samples_prev + samples_curr
- for samples_prev, samples_curr in zip(down_block_res_samples, down_samples)
- ]
- mid_block_res_sample += mid_sample
-
- return down_block_res_samples, mid_block_res_sample
-
-
-class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
- r"""
- Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
-
- This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
- library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
-
- In addition the pipeline inherits the following loading methods:
- - *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
-
- Args:
- vae ([`AutoencoderKL`]):
- Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
- text_encoder ([`CLIPTextModel`]):
- Frozen text-encoder. Stable Diffusion uses the text portion of
- [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
- the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
- tokenizer (`CLIPTokenizer`):
- Tokenizer of class
- [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
- unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
- controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
- Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets
- as a list, the outputs from each ControlNet are added together to create one combined additional
- conditioning.
- scheduler ([`SchedulerMixin`]):
- A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
- [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
- safety_checker ([`StableDiffusionSafetyChecker`]):
- Classification module that estimates whether generated images could be considered offensive or harmful.
- Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
- feature_extractor ([`CLIPImageProcessor`]):
- Model that extracts features from generated images to be used as inputs for the `safety_checker`.
- """
- _optional_components = ["safety_checker", "feature_extractor"]
-
- def __init__(
- self,
- vae: AutoencoderKL,
- text_encoder: CLIPTextModel,
- tokenizer: CLIPTokenizer,
- unet: UNet2DConditionModel,
- controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
- scheduler: KarrasDiffusionSchedulers,
- safety_checker: StableDiffusionSafetyChecker,
- feature_extractor: CLIPImageProcessor,
- requires_safety_checker: bool = True,
- ):
- super().__init__()
-
- if safety_checker is None and requires_safety_checker:
- logger.warning(
- f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
- " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
- " results in services or applications open to the public. Both the diffusers team and Hugging Face"
- " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
- " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
- " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
- )
-
- if safety_checker is not None and feature_extractor is None:
- raise ValueError(
- "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
- " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
- )
-
- if isinstance(controlnet, (list, tuple)):
- controlnet = MultiControlNetModel(controlnet)
-
- self.register_modules(
- vae=vae,
- text_encoder=text_encoder,
- tokenizer=tokenizer,
- unet=unet,
- controlnet=controlnet,
- scheduler=scheduler,
- safety_checker=safety_checker,
- feature_extractor=feature_extractor,
- )
- self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
- self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
- self.register_to_config(requires_safety_checker=requires_safety_checker)
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
- def enable_vae_slicing(self):
- r"""
- Enable sliced VAE decoding.
-
- When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
- steps. This is useful to save some memory and allow larger batch sizes.
- """
- self.vae.enable_slicing()
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
- def disable_vae_slicing(self):
- r"""
- Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
- computing decoding in one step.
- """
- self.vae.disable_slicing()
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
- def enable_vae_tiling(self):
- r"""
- Enable tiled VAE decoding.
-
- When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
- several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
- """
- self.vae.enable_tiling()
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
- def disable_vae_tiling(self):
- r"""
- Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
- computing decoding in one step.
- """
- self.vae.disable_tiling()
-
- def enable_sequential_cpu_offload(self, gpu_id=0):
- r"""
- Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
- text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
- `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
- Note that offloading happens on a submodule basis. Memory savings are higher than with
- `enable_model_cpu_offload`, but performance is lower.
- """
- if is_accelerate_available():
- from accelerate import cpu_offload
- else:
- raise ImportError("Please install accelerate via `pip install accelerate`")
-
- device = torch.device(f"cuda:{gpu_id}")
-
- for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.controlnet]:
- cpu_offload(cpu_offloaded_model, device)
-
- if self.safety_checker is not None:
- cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
-
- def enable_model_cpu_offload(self, gpu_id=0):
- r"""
- Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
- to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
- method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
- `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
- """
- if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
- from accelerate import cpu_offload_with_hook
- else:
- raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
-
- device = torch.device(f"cuda:{gpu_id}")
-
- hook = None
- for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
- _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
-
- if self.safety_checker is not None:
- # the safety checker can offload the vae again
- _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
-
- # control net hook has be manually offloaded as it alternates with unet
- cpu_offload_with_hook(self.controlnet, device)
-
- # We'll offload the last model manually.
- self.final_offload_hook = hook
-
- @property
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
- def _execution_device(self):
- r"""
- Returns the device on which the pipeline's models will be executed. After calling
- `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
- hooks.
- """
- if not hasattr(self.unet, "_hf_hook"):
- return self.device
- for module in self.unet.modules():
- if (
- hasattr(module, "_hf_hook")
- and hasattr(module._hf_hook, "execution_device")
- and module._hf_hook.execution_device is not None
- ):
- return torch.device(module._hf_hook.execution_device)
- return self.device
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
- def _encode_prompt(
- self,
- prompt,
- device,
- num_images_per_prompt,
- do_classifier_free_guidance,
- negative_prompt=None,
- prompt_embeds: Optional[torch.FloatTensor] = None,
- negative_prompt_embeds: Optional[torch.FloatTensor] = None,
- ):
- r"""
- Encodes the prompt into text encoder hidden states.
-
- Args:
- prompt (`str` or `List[str]`, *optional*):
- prompt to be encoded
- device: (`torch.device`):
- torch device
- num_images_per_prompt (`int`):
- number of images that should be generated per prompt
- do_classifier_free_guidance (`bool`):
- whether to use classifier free guidance or not
- negative_prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts not to guide the image generation. If not defined, one has to pass
- `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
- less than `1`).
- prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
- provided, text embeddings will be generated from `prompt` input argument.
- negative_prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
- weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
- argument.
- """
- if prompt is not None and isinstance(prompt, str):
- batch_size = 1
- elif prompt is not None and isinstance(prompt, list):
- batch_size = len(prompt)
- else:
- batch_size = prompt_embeds.shape[0]
-
- if prompt_embeds is None:
- # textual inversion: procecss multi-vector tokens if necessary
- if isinstance(self, TextualInversionLoaderMixin):
- prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
-
- text_inputs = self.tokenizer(
- prompt,
- padding="max_length",
- max_length=self.tokenizer.model_max_length,
- truncation=True,
- return_tensors="pt",
- )
- text_input_ids = text_inputs.input_ids
- untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
-
- if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
- text_input_ids, untruncated_ids
- ):
- removed_text = self.tokenizer.batch_decode(
- untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
- )
- logger.warning(
- "The following part of your input was truncated because CLIP can only handle sequences up to"
- f" {self.tokenizer.model_max_length} tokens: {removed_text}"
- )
-
- if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
- attention_mask = text_inputs.attention_mask.to(device)
- else:
- attention_mask = None
-
- prompt_embeds = self.text_encoder(
- text_input_ids.to(device),
- attention_mask=attention_mask,
- )
- prompt_embeds = prompt_embeds[0]
-
- prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
-
- bs_embed, seq_len, _ = prompt_embeds.shape
- # duplicate text embeddings for each generation per prompt, using mps friendly method
- prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
- prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
-
- # get unconditional embeddings for classifier free guidance
- if do_classifier_free_guidance and negative_prompt_embeds is None:
- uncond_tokens: List[str]
- if negative_prompt is None:
- uncond_tokens = [""] * batch_size
- elif prompt is not None and type(prompt) is not type(negative_prompt):
- raise TypeError(
- f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
- f" {type(prompt)}."
- )
- elif isinstance(negative_prompt, str):
- uncond_tokens = [negative_prompt]
- elif batch_size != len(negative_prompt):
- raise ValueError(
- f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
- f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
- " the batch size of `prompt`."
- )
- else:
- uncond_tokens = negative_prompt
-
- # textual inversion: procecss multi-vector tokens if necessary
- if isinstance(self, TextualInversionLoaderMixin):
- uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
-
- max_length = prompt_embeds.shape[1]
- uncond_input = self.tokenizer(
- uncond_tokens,
- padding="max_length",
- max_length=max_length,
- truncation=True,
- return_tensors="pt",
- )
-
- if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
- attention_mask = uncond_input.attention_mask.to(device)
- else:
- attention_mask = None
-
- negative_prompt_embeds = self.text_encoder(
- uncond_input.input_ids.to(device),
- attention_mask=attention_mask,
- )
- negative_prompt_embeds = negative_prompt_embeds[0]
-
- if do_classifier_free_guidance:
- # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
- seq_len = negative_prompt_embeds.shape[1]
-
- negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
-
- negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
- negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
-
- # For classifier free guidance, we need to do two forward passes.
- # Here we concatenate the unconditional and text embeddings into a single batch
- # to avoid doing two forward passes
- prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
-
- return prompt_embeds
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
- def run_safety_checker(self, image, device, dtype):
- if self.safety_checker is None:
- has_nsfw_concept = None
- else:
- if torch.is_tensor(image):
- feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
- else:
- feature_extractor_input = self.image_processor.numpy_to_pil(image)
- safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
- image, has_nsfw_concept = self.safety_checker(
- images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
- )
- return image, has_nsfw_concept
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
- def decode_latents(self, latents):
- warnings.warn(
- "The decode_latents method is deprecated and will be removed in a future version. Please"
- " use VaeImageProcessor instead",
- FutureWarning,
- )
- latents = 1 / self.vae.config.scaling_factor * latents
- image = self.vae.decode(latents, return_dict=False)[0]
- image = (image / 2 + 0.5).clamp(0, 1)
- # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
- image = image.cpu().permute(0, 2, 3, 1).float().numpy()
- return image
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
- def prepare_extra_step_kwargs(self, generator, eta):
- # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
- # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
- # and should be between [0, 1]
-
- accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
- extra_step_kwargs = {}
- if accepts_eta:
- extra_step_kwargs["eta"] = eta
-
- # check if the scheduler accepts generator
- accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
- if accepts_generator:
- extra_step_kwargs["generator"] = generator
- return extra_step_kwargs
-
- def check_inputs(
- self,
- prompt,
- image,
- height,
- width,
- callback_steps,
- negative_prompt=None,
- prompt_embeds=None,
- negative_prompt_embeds=None,
- controlnet_conditioning_scale=1.0,
- ):
- if height % 8 != 0 or width % 8 != 0:
- raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
-
- if (callback_steps is None) or (
- callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
- ):
- raise ValueError(
- f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
- f" {type(callback_steps)}."
- )
-
- if prompt is not None and prompt_embeds is not None:
- raise ValueError(
- f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
- " only forward one of the two."
- )
- elif prompt is None and prompt_embeds is None:
- raise ValueError(
- "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
- )
- elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
- raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
-
- if negative_prompt is not None and negative_prompt_embeds is not None:
- raise ValueError(
- f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
- f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
- )
-
- if prompt_embeds is not None and negative_prompt_embeds is not None:
- if prompt_embeds.shape != negative_prompt_embeds.shape:
- raise ValueError(
- "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
- f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
- f" {negative_prompt_embeds.shape}."
- )
-
- # `prompt` needs more sophisticated handling when there are multiple
- # conditionings.
- if isinstance(self.controlnet, MultiControlNetModel):
- if isinstance(prompt, list):
- logger.warning(
- f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
- " prompts. The conditionings will be fixed across the prompts."
- )
-
- # Check `image`
- is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
- self.controlnet, torch._dynamo.eval_frame.OptimizedModule
- )
- if (
- isinstance(self.controlnet, ControlNetModel)
- or is_compiled
- and isinstance(self.controlnet._orig_mod, ControlNetModel)
- ):
- self.check_image(image, prompt, prompt_embeds)
- elif (
- isinstance(self.controlnet, MultiControlNetModel)
- or is_compiled
- and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
- ):
- if not isinstance(image, list):
- raise TypeError("For multiple controlnets: `image` must be type `list`")
-
- # When `image` is a nested list:
- # (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
- elif any(isinstance(i, list) for i in image):
- raise ValueError("A single batch of multiple conditionings are supported at the moment.")
- elif len(image) != len(self.controlnet.nets):
- raise ValueError(
- "For multiple controlnets: `image` must have the same length as the number of controlnets."
- )
-
- for image_ in image:
- self.check_image(image_, prompt, prompt_embeds)
- else:
- assert False
-
- # Check `controlnet_conditioning_scale`
- if (
- isinstance(self.controlnet, ControlNetModel)
- or is_compiled
- and isinstance(self.controlnet._orig_mod, ControlNetModel)
- ):
- if not isinstance(controlnet_conditioning_scale, float):
- raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
- elif (
- isinstance(self.controlnet, MultiControlNetModel)
- or is_compiled
- and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
- ):
- if isinstance(controlnet_conditioning_scale, list):
- if any(isinstance(i, list) for i in controlnet_conditioning_scale):
- raise ValueError("A single batch of multiple conditionings are supported at the moment.")
- elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
- self.controlnet.nets
- ):
- raise ValueError(
- "For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
- " the same length as the number of controlnets"
- )
- else:
- assert False
-
- def check_image(self, image, prompt, prompt_embeds):
- image_is_pil = isinstance(image, PIL.Image.Image)
- image_is_tensor = isinstance(image, torch.Tensor)
- image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
- image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
-
- if not image_is_pil and not image_is_tensor and not image_is_pil_list and not image_is_tensor_list:
- raise TypeError(
- "image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
- )
-
- if image_is_pil:
- image_batch_size = 1
- elif image_is_tensor:
- image_batch_size = image.shape[0]
- elif image_is_pil_list:
- image_batch_size = len(image)
- elif image_is_tensor_list:
- image_batch_size = len(image)
-
- if prompt is not None and isinstance(prompt, str):
- prompt_batch_size = 1
- elif prompt is not None and isinstance(prompt, list):
- prompt_batch_size = len(prompt)
- elif prompt_embeds is not None:
- prompt_batch_size = prompt_embeds.shape[0]
-
- if image_batch_size != 1 and image_batch_size != prompt_batch_size:
- raise ValueError(
- f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
- )
-
- def prepare_image(
- self,
- image,
- width,
- height,
- batch_size,
- num_images_per_prompt,
- device,
- dtype,
- do_classifier_free_guidance=False,
- guess_mode=False,
- ):
- if not isinstance(image, torch.Tensor):
- if isinstance(image, PIL.Image.Image):
- image = [image]
-
- if isinstance(image[0], PIL.Image.Image):
- images = []
-
- for image_ in image:
- image_ = image_.convert("RGB")
- image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
- image_ = np.array(image_)
- image_ = image_[None, :]
- images.append(image_)
-
- image = images
-
- image = np.concatenate(image, axis=0)
- image = np.array(image).astype(np.float32) / 255.0
- image = image.transpose(0, 3, 1, 2)
- image = torch.from_numpy(image)
- elif isinstance(image[0], torch.Tensor):
- image = torch.cat(image, dim=0)
-
- image_batch_size = image.shape[0]
-
- if image_batch_size == 1:
- repeat_by = batch_size
- else:
- # image batch size is the same as prompt batch size
- repeat_by = num_images_per_prompt
-
- image = image.repeat_interleave(repeat_by, dim=0)
-
- image = image.to(device=device, dtype=dtype)
-
- if do_classifier_free_guidance and not guess_mode:
- image = torch.cat([image] * 2)
-
- return image
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
- def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
- shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
- if isinstance(generator, list) and len(generator) != batch_size:
- raise ValueError(
- f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
- f" size of {batch_size}. Make sure the batch size matches the length of the generators."
- )
-
- if latents is None:
- latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
- else:
- latents = latents.to(device)
-
- # scale the initial noise by the standard deviation required by the scheduler
- latents = latents * self.scheduler.init_noise_sigma
- return latents
-
- def _default_height_width(self, height, width, image):
- # NOTE: It is possible that a list of images have different
- # dimensions for each image, so just checking the first image
- # is not _exactly_ correct, but it is simple.
- while isinstance(image, list):
- image = image[0]
-
- if height is None:
- if isinstance(image, PIL.Image.Image):
- height = image.height
- elif isinstance(image, torch.Tensor):
- height = image.shape[2]
-
- height = (height // 8) * 8 # round down to nearest multiple of 8
-
- if width is None:
- if isinstance(image, PIL.Image.Image):
- width = image.width
- elif isinstance(image, torch.Tensor):
- width = image.shape[3]
-
- width = (width // 8) * 8 # round down to nearest multiple of 8
-
- return height, width
-
- # override DiffusionPipeline
- def save_pretrained(
- self,
- save_directory: Union[str, os.PathLike],
- safe_serialization: bool = False,
- variant: Optional[str] = None,
- ):
- if isinstance(self.controlnet, ControlNetModel):
- super().save_pretrained(save_directory, safe_serialization, variant)
- else:
- raise NotImplementedError("Currently, the `save_pretrained()` is not implemented for Multi-ControlNet.")
-
- @torch.no_grad()
- @replace_example_docstring(EXAMPLE_DOC_STRING)
- def __call__(
- self,
- prompt: Union[str, List[str]] = None,
- image: Union[torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]] = None,
- height: Optional[int] = None,
- width: Optional[int] = None,
- num_inference_steps: int = 50,
- guidance_scale: float = 7.5,
- negative_prompt: Optional[Union[str, List[str]]] = None,
- num_images_per_prompt: Optional[int] = 1,
- eta: float = 0.0,
- generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
- latents: Optional[torch.FloatTensor] = None,
- prompt_embeds: Optional[torch.FloatTensor] = None,
- negative_prompt_embeds: Optional[torch.FloatTensor] = None,
- output_type: Optional[str] = "pil",
- return_dict: bool = True,
- callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
- callback_steps: int = 1,
- cross_attention_kwargs: Optional[Dict[str, Any]] = None,
- controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
- guess_mode: bool = False,
- ):
- r"""
- Function invoked when calling the pipeline for generation.
-
- Args:
- prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
- instead.
- image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`,
- `List[List[torch.FloatTensor]]`, or `List[List[PIL.Image.Image]]`):
- The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
- the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
- also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
- height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
- specified in init, images must be passed as a list such that each element of the list can be correctly
- batched for input to a single controlnet.
- height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
- The height in pixels of the generated image.
- width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
- The width in pixels of the generated image.
- num_inference_steps (`int`, *optional*, defaults to 50):
- The number of denoising steps. More denoising steps usually lead to a higher quality image at the
- expense of slower inference.
- guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
- negative_prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts not to guide the image generation. If not defined, one has to pass
- `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
- less than `1`).
- num_images_per_prompt (`int`, *optional*, defaults to 1):
- The number of images to generate per prompt.
- eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
- generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
- One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
- to make generation deterministic.
- latents (`torch.FloatTensor`, *optional*):
- Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
- generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
- tensor will ge generated by sampling using the supplied random `generator`.
- prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
- provided, text embeddings will be generated from `prompt` input argument.
- negative_prompt_embeds (`torch.FloatTensor`, *optional*):
- Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
- weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
- argument.
- output_type (`str`, *optional*, defaults to `"pil"`):
- The output format of the generate image. Choose between
- [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
- return_dict (`bool`, *optional*, defaults to `True`):
- Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
- plain tuple.
- callback (`Callable`, *optional*):
- A function that will be called every `callback_steps` steps during inference. The function will be
- called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
- callback_steps (`int`, *optional*, defaults to 1):
- The frequency at which the `callback` function will be called. If not specified, the callback will be
- called at every step.
- cross_attention_kwargs (`dict`, *optional*):
- A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
- `self.processor` in
- [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
- controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
- The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
- to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
- corresponding scale as a list.
- guess_mode (`bool`, *optional*, defaults to `False`):
- In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
- you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
-
- Examples:
-
- Returns:
- [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
- [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
- When returning a tuple, the first element is a list with the generated images, and the second element is a
- list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
- (nsfw) content, according to the `safety_checker`.
- """
- # 0. Default height and width to unet
- height, width = self._default_height_width(height, width, image)
-
- # 1. Check inputs. Raise error if not correct
- self.check_inputs(
- prompt,
- image,
- height,
- width,
- callback_steps,
- negative_prompt,
- prompt_embeds,
- negative_prompt_embeds,
- controlnet_conditioning_scale,
- )
-
- # 2. Define call parameters
- if prompt is not None and isinstance(prompt, str):
- batch_size = 1
- elif prompt is not None and isinstance(prompt, list):
- batch_size = len(prompt)
- else:
- batch_size = prompt_embeds.shape[0]
-
- device = self._execution_device
- # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
- # corresponds to doing no classifier free guidance.
- do_classifier_free_guidance = guidance_scale > 1.0
-
- if isinstance(self.controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
- controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(self.controlnet.nets)
-
- global_pool_conditions = (
- self.controlnet.config.global_pool_conditions
- if isinstance(self.controlnet, ControlNetModel)
- else self.controlnet.nets[0].config.global_pool_conditions
- )
- guess_mode = guess_mode or global_pool_conditions
-
- # 3. Encode input prompt
- prompt_embeds = self._encode_prompt(
- prompt,
- device,
- num_images_per_prompt,
- do_classifier_free_guidance,
- negative_prompt,
- prompt_embeds=prompt_embeds,
- negative_prompt_embeds=negative_prompt_embeds,
- )
-
- # 4. Prepare image
- is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
- self.controlnet, torch._dynamo.eval_frame.OptimizedModule
- )
- if (
- isinstance(self.controlnet, ControlNetModel)
- or is_compiled
- and isinstance(self.controlnet._orig_mod, ControlNetModel)
- ):
- image = self.prepare_image(
- image=image,
- width=width,
- height=height,
- batch_size=batch_size * num_images_per_prompt,
- num_images_per_prompt=num_images_per_prompt,
- device=device,
- dtype=self.controlnet.dtype,
- do_classifier_free_guidance=do_classifier_free_guidance,
- guess_mode=guess_mode,
- )
- elif (
- isinstance(self.controlnet, MultiControlNetModel)
- or is_compiled
- and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
- ):
- images = []
-
- for image_ in image:
- image_ = self.prepare_image(
- image=image_,
- width=width,
- height=height,
- batch_size=batch_size * num_images_per_prompt,
- num_images_per_prompt=num_images_per_prompt,
- device=device,
- dtype=self.controlnet.dtype,
- do_classifier_free_guidance=do_classifier_free_guidance,
- guess_mode=guess_mode,
- )
-
- images.append(image_)
-
- image = images
- else:
- assert False
-
- # 5. Prepare timesteps
- self.scheduler.set_timesteps(num_inference_steps, device=device)
- timesteps = self.scheduler.timesteps
-
- # 6. Prepare latent variables
- num_channels_latents = self.unet.config.in_channels
- latents = self.prepare_latents(
- batch_size * num_images_per_prompt,
- num_channels_latents,
- height,
- width,
- prompt_embeds.dtype,
- device,
- generator,
- latents,
- )
-
- # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
- extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
-
- # 8. Denoising loop
- num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
- with self.progress_bar(total=num_inference_steps) as progress_bar:
- for i, t in enumerate(timesteps):
- # expand the latents if we are doing classifier free guidance
- latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
- latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
-
- # controlnet(s) inference
- if guess_mode and do_classifier_free_guidance:
- # Infer ControlNet only for the conditional batch.
- controlnet_latent_model_input = latents
- controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
- else:
- controlnet_latent_model_input = latent_model_input
- controlnet_prompt_embeds = prompt_embeds
-
- down_block_res_samples, mid_block_res_sample = self.controlnet(
- controlnet_latent_model_input,
- t,
- encoder_hidden_states=controlnet_prompt_embeds,
- controlnet_cond=image,
- conditioning_scale=controlnet_conditioning_scale,
- guess_mode=guess_mode,
- return_dict=False,
- )
-
- if guess_mode and do_classifier_free_guidance:
- # Infered ControlNet only for the conditional batch.
- # To apply the output of ControlNet to both the unconditional and conditional batches,
- # add 0 to the unconditional batch to keep it unchanged.
- down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
- mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
-
- # predict the noise residual
- noise_pred = self.unet(
- latent_model_input,
- t,
- encoder_hidden_states=prompt_embeds,
- cross_attention_kwargs=cross_attention_kwargs,
- down_block_additional_residuals=down_block_res_samples,
- mid_block_additional_residual=mid_block_res_sample,
- return_dict=False,
- )[0]
-
- # perform guidance
- if do_classifier_free_guidance:
- noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
- noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
-
- # compute the previous noisy sample x_t -> x_t-1
- latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
-
- # call the callback, if provided
- if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
- progress_bar.update()
- if callback is not None and i % callback_steps == 0:
- callback(i, t, latents)
-
- # If we do sequential model offloading, let's offload unet and controlnet
- # manually for max memory savings
- if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
- self.unet.to("cpu")
- self.controlnet.to("cpu")
- torch.cuda.empty_cache()
-
- if not output_type == "latent":
- image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
- image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
- else:
- image = latents
- has_nsfw_concept = None
-
- if has_nsfw_concept is None:
- do_denormalize = [True] * image.shape[0]
- else:
- do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
-
- image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
-
- # Offload last model to CPU
- if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
- self.final_offload_hook.offload()
-
- if not return_dict:
- return (image, has_nsfw_concept)
-
- return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/src/diffusers/utils/dummy_torch_and_transformers_objects.py b/src/diffusers/utils/dummy_torch_and_transformers_objects.py
index f3708107e82a..4c6c595c41d8 100644
--- a/src/diffusers/utils/dummy_torch_and_transformers_objects.py
+++ b/src/diffusers/utils/dummy_torch_and_transformers_objects.py
@@ -212,6 +212,36 @@ def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch", "transformers"])
+class StableDiffusionControlNetImg2ImgPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionControlNetInpaintPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
class StableDiffusionControlNetPipeline(metaclass=DummyObject):
_backends = ["torch", "transformers"]
diff --git a/tests/pipelines/controlnet/__init__.py b/tests/pipelines/controlnet/__init__.py
new file mode 100644
index 000000000000..e69de29bb2d1
diff --git a/tests/pipelines/stable_diffusion/test_stable_diffusion_controlnet.py b/tests/pipelines/controlnet/test_controlnet.py
similarity index 98%
rename from tests/pipelines/stable_diffusion/test_stable_diffusion_controlnet.py
rename to tests/pipelines/controlnet/test_controlnet.py
index bd1470f5ebd1..0453bb38e1ee 100644
--- a/tests/pipelines/stable_diffusion/test_stable_diffusion_controlnet.py
+++ b/tests/pipelines/controlnet/test_controlnet.py
@@ -34,7 +34,10 @@
from diffusers.utils.import_utils import is_xformers_available
from diffusers.utils.testing_utils import require_torch_gpu
-from ..pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_PARAMS
+from ..pipeline_params import (
+ TEXT_TO_IMAGE_BATCH_PARAMS,
+ TEXT_TO_IMAGE_PARAMS,
+)
from ..test_pipelines_common import PipelineLatentTesterMixin, PipelineTesterMixin
@@ -42,7 +45,7 @@
torch.use_deterministic_algorithms(True)
-class StableDiffusionControlNetPipelineFastTests(PipelineLatentTesterMixin, PipelineTesterMixin, unittest.TestCase):
+class ControlNetPipelineFastTests(PipelineLatentTesterMixin, PipelineTesterMixin, unittest.TestCase):
pipeline_class = StableDiffusionControlNetPipeline
params = TEXT_TO_IMAGE_PARAMS
batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
@@ -155,6 +158,7 @@ class StableDiffusionMultiControlNetPipelineFastTests(PipelineTesterMixin, unitt
pipeline_class = StableDiffusionControlNetPipeline
params = TEXT_TO_IMAGE_PARAMS
batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
+ image_params = frozenset([]) # TO_DO: add image_params once refactored VaeImageProcessor.preprocess
def get_dummy_components(self):
torch.manual_seed(0)
@@ -307,7 +311,7 @@ def test_save_load_optional_components(self):
@slow
@require_torch_gpu
-class StableDiffusionControlNetPipelineSlowTests(unittest.TestCase):
+class ControlNetPipelineSlowTests(unittest.TestCase):
def tearDown(self):
super().tearDown()
gc.collect()
diff --git a/tests/pipelines/controlnet/test_controlnet_img2img.py b/tests/pipelines/controlnet/test_controlnet_img2img.py
new file mode 100644
index 000000000000..b83a8af2778b
--- /dev/null
+++ b/tests/pipelines/controlnet/test_controlnet_img2img.py
@@ -0,0 +1,366 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This model implementation is heavily inspired by https://github.com/haofanwang/ControlNet-for-Diffusers/
+
+import gc
+import random
+import tempfile
+import unittest
+
+import numpy as np
+import torch
+from PIL import Image
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ ControlNetModel,
+ DDIMScheduler,
+ StableDiffusionControlNetImg2ImgPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_controlnet import MultiControlNetModel
+from diffusers.utils import floats_tensor, load_image, load_numpy, randn_tensor, slow, torch_device
+from diffusers.utils.import_utils import is_xformers_available
+from diffusers.utils.testing_utils import require_torch_gpu
+
+from ..pipeline_params import (
+ TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS,
+ TEXT_GUIDED_IMAGE_VARIATION_PARAMS,
+)
+from ..test_pipelines_common import PipelineLatentTesterMixin, PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+torch.use_deterministic_algorithms(True)
+
+
+class ControlNetImg2ImgPipelineFastTests(PipelineLatentTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionControlNetImg2ImgPipeline
+ params = TEXT_GUIDED_IMAGE_VARIATION_PARAMS - {"height", "width"}
+ batch_params = TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS
+ image_params = frozenset([]) # TO_DO: add image_params once refactored VaeImageProcessor.preprocess
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ torch.manual_seed(0)
+ controlnet = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "controlnet": controlnet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+
+ controlnet_embedder_scale_factor = 2
+ control_image = randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ )
+ image = floats_tensor(control_image.shape, rng=random.Random(seed)).to(device)
+ image = image.cpu().permute(0, 2, 3, 1)[0]
+ image = Image.fromarray(np.uint8(image)).convert("RGB").resize((64, 64))
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ "image": image,
+ "control_image": control_image,
+ }
+
+ return inputs
+
+ def test_attention_slicing_forward_pass(self):
+ return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_attention_forwardGenerator_pass(self):
+ self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(expected_max_diff=2e-3)
+
+
+class StableDiffusionMultiControlNetPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionControlNetImg2ImgPipeline
+ params = TEXT_GUIDED_IMAGE_VARIATION_PARAMS - {"height", "width"}
+ batch_params = TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS
+ image_params = frozenset([]) # TO_DO: add image_params once refactored VaeImageProcessor.preprocess
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ torch.manual_seed(0)
+ controlnet1 = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ controlnet2 = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ controlnet = MultiControlNetModel([controlnet1, controlnet2])
+
+ components = {
+ "unet": unet,
+ "controlnet": controlnet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+
+ controlnet_embedder_scale_factor = 2
+
+ control_image = [
+ randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ ),
+ randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ ),
+ ]
+
+ image = floats_tensor(control_image[0].shape, rng=random.Random(seed)).to(device)
+ image = image.cpu().permute(0, 2, 3, 1)[0]
+ image = Image.fromarray(np.uint8(image)).convert("RGB").resize((64, 64))
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ "image": image,
+ "control_image": control_image,
+ }
+
+ return inputs
+
+ def test_attention_slicing_forward_pass(self):
+ return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_attention_forwardGenerator_pass(self):
+ self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(expected_max_diff=2e-3)
+
+ def test_save_pretrained_raise_not_implemented_exception(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ with tempfile.TemporaryDirectory() as tmpdir:
+ try:
+ # save_pretrained is not implemented for Multi-ControlNet
+ pipe.save_pretrained(tmpdir)
+ except NotImplementedError:
+ pass
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_float16(self):
+ ...
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_local(self):
+ ...
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_optional_components(self):
+ ...
+
+
+@slow
+@require_torch_gpu
+class ControlNetImg2ImgPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_canny(self):
+ controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
+
+ pipe = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
+ )
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ prompt = "evil space-punk bird"
+ control_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
+ ).resize((512, 512))
+ image = load_image(
+ "https://huggingface.co/lllyasviel/sd-controlnet-canny/resolve/main/images/bird.png"
+ ).resize((512, 512))
+
+ output = pipe(
+ prompt,
+ image,
+ control_image=control_image,
+ generator=generator,
+ output_type="np",
+ num_inference_steps=50,
+ strength=0.6,
+ )
+
+ image = output.images[0]
+
+ assert image.shape == (512, 512, 3)
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/img2img.npy"
+ )
+
+ assert np.abs(expected_image - image).max() < 9e-2
diff --git a/tests/pipelines/controlnet/test_controlnet_inpaint.py b/tests/pipelines/controlnet/test_controlnet_inpaint.py
new file mode 100644
index 000000000000..786b0e608ef0
--- /dev/null
+++ b/tests/pipelines/controlnet/test_controlnet_inpaint.py
@@ -0,0 +1,379 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This model implementation is heavily based on:
+
+import gc
+import random
+import tempfile
+import unittest
+
+import numpy as np
+import torch
+from PIL import Image
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ ControlNetModel,
+ DDIMScheduler,
+ StableDiffusionControlNetInpaintPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_controlnet import MultiControlNetModel
+from diffusers.utils import floats_tensor, load_image, load_numpy, randn_tensor, slow, torch_device
+from diffusers.utils.import_utils import is_xformers_available
+from diffusers.utils.testing_utils import require_torch_gpu
+
+from ..pipeline_params import (
+ TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS,
+ TEXT_GUIDED_IMAGE_INPAINTING_PARAMS,
+)
+from ..test_pipelines_common import PipelineLatentTesterMixin, PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+torch.use_deterministic_algorithms(True)
+
+
+class ControlNetInpaintPipelineFastTests(PipelineLatentTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionControlNetInpaintPipeline
+ params = TEXT_GUIDED_IMAGE_INPAINTING_PARAMS
+ batch_params = TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS
+ image_params = frozenset([])
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=9,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ torch.manual_seed(0)
+ controlnet = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "controlnet": controlnet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+
+ controlnet_embedder_scale_factor = 2
+ control_image = randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ )
+ init_image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)).to(device)
+ init_image = init_image.cpu().permute(0, 2, 3, 1)[0]
+
+ image = Image.fromarray(np.uint8(init_image)).convert("RGB").resize((64, 64))
+ mask_image = Image.fromarray(np.uint8(init_image + 4)).convert("RGB").resize((64, 64))
+
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ "image": image,
+ "mask_image": mask_image,
+ "control_image": control_image,
+ }
+
+ return inputs
+
+ def test_attention_slicing_forward_pass(self):
+ return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_attention_forwardGenerator_pass(self):
+ self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(expected_max_diff=2e-3)
+
+
+class MultiControlNetInpaintPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionControlNetInpaintPipeline
+ params = TEXT_GUIDED_IMAGE_INPAINTING_PARAMS
+ batch_params = TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=9,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ torch.manual_seed(0)
+ controlnet1 = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ controlnet2 = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ controlnet = MultiControlNetModel([controlnet1, controlnet2])
+
+ components = {
+ "unet": unet,
+ "controlnet": controlnet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+
+ controlnet_embedder_scale_factor = 2
+
+ control_image = [
+ randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ ),
+ randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ ),
+ ]
+ init_image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)).to(device)
+ init_image = init_image.cpu().permute(0, 2, 3, 1)[0]
+
+ image = Image.fromarray(np.uint8(init_image)).convert("RGB").resize((64, 64))
+ mask_image = Image.fromarray(np.uint8(init_image + 4)).convert("RGB").resize((64, 64))
+
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ "image": image,
+ "mask_image": mask_image,
+ "control_image": control_image,
+ }
+
+ return inputs
+
+ def test_attention_slicing_forward_pass(self):
+ return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_attention_forwardGenerator_pass(self):
+ self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(expected_max_diff=2e-3)
+
+ def test_save_pretrained_raise_not_implemented_exception(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ with tempfile.TemporaryDirectory() as tmpdir:
+ try:
+ # save_pretrained is not implemented for Multi-ControlNet
+ pipe.save_pretrained(tmpdir)
+ except NotImplementedError:
+ pass
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_float16(self):
+ ...
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_local(self):
+ ...
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_optional_components(self):
+ ...
+
+
+@slow
+@require_torch_gpu
+class ControlNetInpaintPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_canny(self):
+ controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
+
+ pipe = StableDiffusionControlNetInpaintPipeline.from_pretrained(
+ "runwayml/stable-diffusion-inpainting", safety_checker=None, controlnet=controlnet
+ )
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ image = load_image(
+ "https://huggingface.co/lllyasviel/sd-controlnet-canny/resolve/main/images/bird.png"
+ ).resize((512, 512))
+
+ mask_image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint/input_bench_mask.png"
+ ).resize((512, 512))
+
+ prompt = "pitch black hole"
+
+ control_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
+ ).resize((512, 512))
+
+ output = pipe(
+ prompt,
+ image=image,
+ mask_image=mask_image,
+ control_image=control_image,
+ generator=generator,
+ output_type="np",
+ num_inference_steps=3,
+ )
+
+ image = output.images[0]
+
+ assert image.shape == (512, 512, 3)
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/inpaint.npy"
+ )
+
+ assert np.abs(expected_image - image).max() < 9e-2
diff --git a/tests/pipelines/stable_diffusion/test_stable_diffusion_flax_controlnet.py b/tests/pipelines/controlnet/test_flax_controlnet.py
similarity index 98%
rename from tests/pipelines/stable_diffusion/test_stable_diffusion_flax_controlnet.py
rename to tests/pipelines/controlnet/test_flax_controlnet.py
index 268c01320177..4ad75b407acc 100644
--- a/tests/pipelines/stable_diffusion/test_stable_diffusion_flax_controlnet.py
+++ b/tests/pipelines/controlnet/test_flax_controlnet.py
@@ -30,7 +30,7 @@
@slow
@require_flax
-class FlaxStableDiffusionControlNetPipelineIntegrationTests(unittest.TestCase):
+class FlaxControlNetPipelineIntegrationTests(unittest.TestCase):
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
diff --git a/tests/pipelines/stable_diffusion/test_stable_diffusion_image_variation.py b/tests/pipelines/stable_diffusion/test_stable_diffusion_image_variation.py
index 8c27a568d24d..0ce55ae78ae0 100644
--- a/tests/pipelines/stable_diffusion/test_stable_diffusion_image_variation.py
+++ b/tests/pipelines/stable_diffusion/test_stable_diffusion_image_variation.py
@@ -46,9 +46,8 @@ class StableDiffusionImageVariationPipelineFastTests(
pipeline_class = StableDiffusionImageVariationPipeline
params = IMAGE_VARIATION_PARAMS
batch_params = IMAGE_VARIATION_BATCH_PARAMS
- image_params = frozenset(
- []
- ) # TO-DO: update image_params once pipeline is refactored with VaeImageProcessor.preprocess
+ image_params = frozenset([])
+ # TO-DO: update image_params once pipeline is refactored with VaeImageProcessor.preprocess
def get_dummy_components(self):
torch.manual_seed(0)
diff --git a/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py b/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py
index cdf138c4e178..a215e4da6697 100644
--- a/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py
+++ b/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py
@@ -47,9 +47,8 @@ class StableDiffusionInpaintPipelineFastTests(PipelineLatentTesterMixin, Pipelin
pipeline_class = StableDiffusionInpaintPipeline
params = TEXT_GUIDED_IMAGE_INPAINTING_PARAMS
batch_params = TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS
- image_params = frozenset(
- []
- ) # TO-DO: update image_params once pipeline is refactored with VaeImageProcessor.preprocess
+ image_params = frozenset([])
+ # TO-DO: update image_params once pipeline is refactored with VaeImageProcessor.preprocess
def get_dummy_components(self):
torch.manual_seed(0)